





















We'll go in-depth on what, why, and how of text normalization. With code examples written in SpaCy and NLTK Python libraries.
We'll go in-depth on what, why, and how of text normalization. With code examples written in SpaCy and NLTK Python libraries.
By the end of this article, you will have created a basic text normalization pipeline using both spaCy and NLTK:

Textual data is unstructured, it is essentially the written form of a natural language such as English, French, Russian, etc. Although these languages are driven by grammar rules and have defined structures, they’re human constructs, and they tend to follow the inherently random nature of their creator.
Simply put, as we speak or write a natural language, we impart our randomness to it. This can be in the form of something sophisticated such as sarcasm and double entendres, or something as simple as grammatical mistakes, or erratic punctuations.
Why Do We Need Text Normalization?
Computers and algorithms are not good at dealing with randomness. So, when working with textual data it is important to transform the raw text into a form that can be easily interpreted and used by machine learning algorithms. That’s where Text Normalization comes in. When we normalize a natural language we aim to reduce — if not remove — the randomness in it, transforming it into a predefined ‘standard’.
Before we go further with the discussion on normalization, it is important to keep in mind that there is no ‘one-size-fits-all’ set of text normalization tasks that work in all situations. In reality, as we dive deeper into NLP, we see that NLP is not as general as one may think. Despite the abundance of useful general-purpose toolboxes and premade pipelines, the more accurate systems are the ones tailored to the specific use cases. In fact, in some cases, we might not want to normalize the input at all. An AI-based test correcting algorithm would be a good example of such a use case, where wrongness and variety are essential to the functioning of the system.
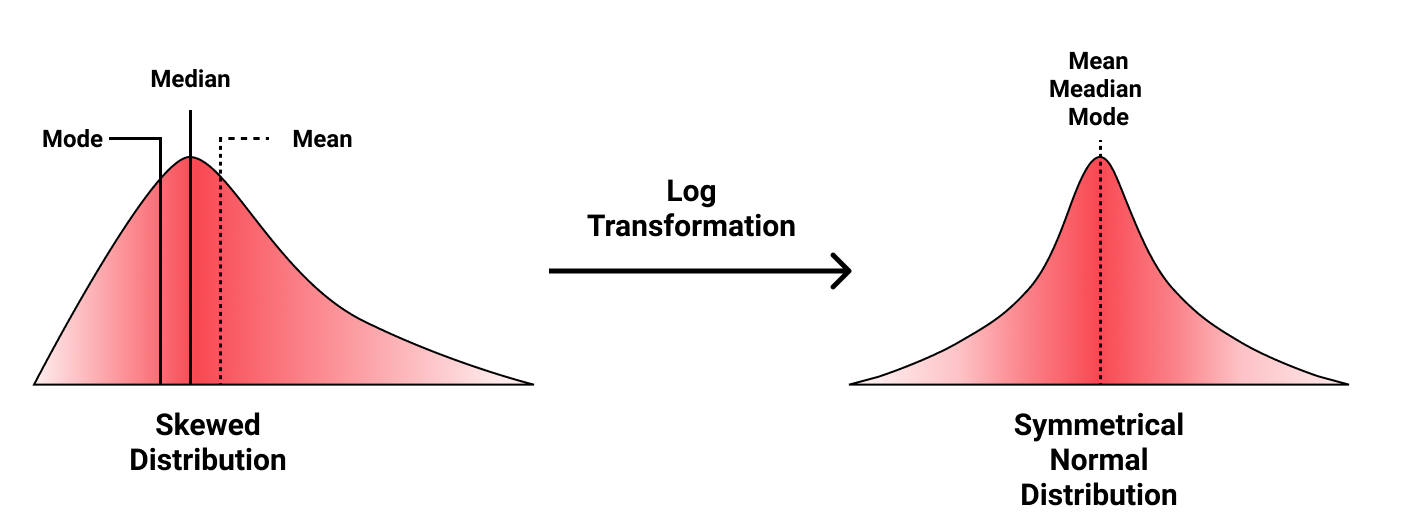
Mathematically speaking, normalization can be thought of as applying the log transform to a skewed probability distribution in an attempt to bring it closer to the normal distribution. When we normalize a natural language input, we’re trying to make things ‘behave as expected’, like the probabilities that follow the normal distribution. Mathematical intuition aside, there are many benefits of normalizing the text input of our NLP systems.
1) Reduce the variation
Normalizing the input reduces the variations leaving us with fewer input variables to deal with. This helps improve overall performance and avoid false negatives, especially in the case of expert systems and information retrieval tasks. How awful would Google’s search engine perform if it only looked for the exact words we typed?
2) Reduce the dimensionality
When working with machine learning algorithms, high dimensionality is a major concern. Text normalization reduces the dimensionality of the input and lowers the amount of computation needed for creating embeddings if our NLP pipeline employs structures like Bags-of-Words or TF-IDF dictionaries.
3) Clean inputs
Normalization helps us catch code-breaking inputs before they are passed to the decision-making NLP algorithm. In this case, we ensure that our inputs will follow a set of rules or a predefined ‘standard’ before being used. Finally, normalization is crucial for making reliable extraction of statistics from natural language inputs.
What Do We Want To Normalize?
Before performing text normalization, we should know exactly what we want to normalize and why. as mentioned before, there is no standard set of normalization tasks, knowing the purpose of the input helps us choose the appropriate steps to apply for normalizing the input. Broadly speaking, there are two things we focus on:
- Vocabulary: We want to minimize the size of our vocabulary in most cases. This is because in NLP, words act as our key features and when we have less variation in these we can achieve our objectives more easily.
- Sentence structure: How do we define a sentence? Does it always end with punctuations? Do stop words carry any meaningful information? Should we remove all punctuation? Or more specific structural constraints like attaining subject-verb-object.
In practice, we normalize the text by breaking these two concerns into easier to tackle problems, here’s a list of some common ones:
- Removal of punctuations and white spaces.
- Replacing word numerals with numbers.

- Standardization of date formats, identification numbers, or any data the might have a defined format.

- Removal of stop words. This is more of a dimensionality reduction-centric step as stop words can be useful in some scenarios. For example, stop words might be vital to identify certain contexts when employing contextual rules for named entity recognition.

- Substitution or deletion of special characters.
- Spell correction. One word can be misspelled in a gazillion ways, spell correction helps reduce the size of the vocabulary.
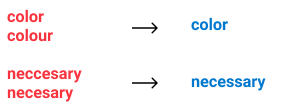
- Normalization or substitution of acronyms

- Normalizing of gender/time/grade variation of verbs with Stemming or Lemmatization.
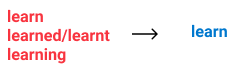
In this article, we’ll go through the implementation of a few of them: stopword and punctuation removal, lemmatization, and stemming. Before we get started, let’s see what they mean.
Tokenization
Before we can start with the normalization tasks we need to perform tokenization. It is the process of segmenting text into smaller units known as tokens. The most common tokenization method is white space tokenization. In this method, white spaces are used to identify and split tokens.

Notice that ‘New-Zealand’ is not split further as the tokenization is based on white spaces only. Another common method is regular expression tokenization which uses regular expression patterns to get the tokens.

Stemming & Lemmatization
In linguistics, a morpheme is defined as the smallest meaningful item in a language. A morpheme is not the same as a word, the main difference between a morpheme and a word is that a morpheme sometimes does not stand alone, but a word, by definition, always stands alone. All tokens in natural languages are basically made up of two components one is morpheme and the other is an inflectional form like prefix or suffix. Take for instance the word resupply, it is made up of ‘re’ as the inflectional form and ‘supply’ as the morpheme.
When we normalize words with the goal to reduce vocabulary size, we convert tokens into their base form. During the normalization process, the inflectional form of the words is removed so the morpheme or base can be obtained. So in our example, the normalized form of ‘resupply’ is ‘supply’.
There are two common methods for normalization - stemming and lemmatization. Let’s see what they are and how they differ.
Stemming
It is a simple rule-based process that reduces the infected or derived form of a word to its word stem. A stemming algorithm would reduce the words ‘fishing’, ‘fished’, and ‘fisher’ to the stem ‘fish’. It is important to note that the stem word may not be identical to the morphological root of the word, or be a word at all. For instance, the Porter algorithm reduces ‘change’, ‘changing’, ‘changes’, ‘changed’, and ‘changer’ to the stem ‘chang’.

Related words map to the same stem even if this stem is not in itself a valid root, this can be sufficient for some use-cases like information retrieval systems and search engines that treat words with the same stem as synonyms.
Lemmatization
Lemmatization is a systematic process that groups the inflected forms of a word so they can be analyzed as a single token, the base form of the words, or lemma. For example, the verb 'to be' may appear as is', 'am', 'are' or 'being'. Here the base form, ‘be’ is called the lemma for the words.

Stemmers operate on a single word without knowledge of the context, and therefore cannot discriminate between words that have different meanings depending on part of speech. On the other hand, Lemmatizers utilize the intended part of speech and meaning of a word in a sentence, as well as within the larger context surrounding that sentence.
This means that lemmatization often yields more ‘accurate’ base words when compared to stemming. Furthermore, since lemmatization is conscious of the general structure and grammar of the text, it can be performed only if the given word has proper parts of the speech tag. For example, if we try to lemmatize the word ‘writing’ as a verb it will be converted to run. But, if we try to lemmatize the same word ‘writing’ as a noun it won’t be transformed.
Text Normalization In Python
The most common sources of text data on the internet are:
- social media data like tweets, posts, comments
- articles texts like news articles and blogs
- conversation data like messages, emails, chats, etc.
For the purposes of this article, we’ll be working with the news article text. To get this data we’ll use News API, you can get your free API key here.
We just use our News API as a source of real-time data. You can use text normalization code on any text input!
Installing Python Libraries
We’ll be using and comparing NLTK and spaCy for the task of normalization, so let’s install them next.
Optionally, install the newscatherapi python module from PyPI or use the requests module to access the API endpoints explicitly.
Let’s fetch a hundred articles related to Bitcoin and cryptocurrencies.
This will return a dictionary that will contain a list of the articles among other things. These articles can be accessed using the ‘articles’ key and have the following form.
Let’s create a list of all article summaries as the rest of the data is largely useless for us right now.
Creating our own rudimentary function for removing punctuations:
Text Normalization With spaCy
spaCy’s nlp() method tokenizes the text to produce a Doc object and then passes it to its processing pipeline. This pipeline includes a parts-of-speech(POS) tagger, a lemmatizer, a parser, and a named entity recognizer(NER) among other things. One thing to keep in mind is that spaCy doesn’t have a method for stemming as they prefer lemmatization over stemming.
If all we wanted to do was tokenize the text we could use the Tokenizer class.
as we’ll be making a speed comparison towards the end, it makes sense to disable the parts of the pipeline that we don’t need. This means we can disable everything but the lemmatizer and the tagger. We keep the tagger because the lemmatizer makes use of the POS tag information.
All that we need to do is pass the text to the pipeline and extract the relevant processed tokens.
Getting the lemmatized tokens:
The spaCy lemmatizer adds a special case for English pronouns, all English pronouns are lemmatized to the special token -PRON-.
Now let’s use spaCy to remove the stop words, and use our remove_punctuations function to deal with punctuations:
Text Normalization With NLTK
Unlike spaCy, NLTK supports stemming as well. There are two prominent
stemmers—Porter stemmer and Snowball stemmer, we’ll use Porter Stemmer for our example. But before we can do that we’ll need to download the tokenizer, lemmatizer, and list of stop words.
We can now import the relevant classes and perform stemming and lemmatization.
Now that we have the tokens; we can use NLTK’s set of stop words and our remove_punctuations function to deal with the punctuations and stop words.
The spaCy results were more readable due to the lack of a stemming process.
spaCy vs NLTK
Let’s use the combined corpus of 100 articles to compare the two modules:
sentence = " ".join(summary)
%%time
spacy_pipeline(sentence)
Total normalized tokens: 7177
CPU times: user 415 ms, sys: 6.81 ms, total: 422 ms
Wall time: 422 ms
%%time
nltk_pipeline(sentence)
Total normalized tokens:7505
CPU times: user 448 ms, sys: 3.48 ms, total: 451 ms
Wall time: 452 ms
Conclusion
Thanks to its more robust lemmatization process, spaCy is able to reduce the corpus to a smaller set of tokens. as far as the speed is concerned, the results can be deceiving. Although the speed might look comparable for our small corpus, in reality, spaCy is far more efficient. It’s important to remember that spaCy is doing an extra operation of tagging the different parts of speech.
Pipeline test code:



.png)






































