





















Learn how to use sentiment analysis to mine insights about from tweets and news articles
By the end of this tutorial, you will be able to write a Sentiment Analysis pipeline using NLTK and transformers: it will detect public sentiment around companies from news headlines and tweets.
DEMO:
Learn how to use sentiment analysis to mine insights from different data sources. We will write a Python script to analyze tweets and news articles to learn about the public sentiment around some tech companies.
In this tutorial, we will:
- build a data pipeline to fetch tweets from Twitter and articles from top news publications
- clean and normalize textual data
- apply pre-trained sentiment analysis finBERT model provided in the transformers module
- visualizing sentiment results
What Is Sentiment Analysis?
Sentiment analysis is the automated text analysis process that identifies and quantifies subjective information in text data.
When we need to understand what someone thinks about a product, service, or company, we get their feedback and store it in the form of an ordinal data point. In fact, most feedback forms and reviews have some form of this:

Nowadays, simple data points are not always representative of customer satisfaction. But people love to share their opinion on social media, so why do not use that? That’s where sentiment analysis comes in handy.Sentiment analysis aims to quantify the sentiment, opinion, or judgment based on what people write online. So it’s no surprise that the most common type of sentiment analysis is ’Polarity detection’ that involves classifying text sentiment as Positive, Negative, or Neutral.
Check out the sentiment analysis model below which tags this tweet as Negative:

Where Is Sentiment Analysis Used?
Marketing: Companies often use sentiment analysis to develop their marketing strategies, and to check how well they perform. In addition to that, sentiment analysis also helps the companies get a better grasp of how well their products and services are being received by the customers.
Politics: For the longest time, pre-election polls served as the only means of evaluating where the candidates stand in an upcoming election. These are rather inaccurate and can be deceiving as they are at the mercy of the voter turn-out. Sentiment analysis makes this process easier by leveraging the free-flowing political discourse on social networking sites.
Public Actions: as dystopian as it may seem, sentiment analysis can be used to look out for “destructive” tendencies in public rallies, protests, and demonstrations.
Twitter Sentiment Analysis With Python
Social networking platforms like Twitter enable businesses to engage with users. But, there’s a lot of data so it can be hard for brands to prioritize which tweets or mentions to respond to first. That's why sentiment analysis has become an essential part of social media marketing strategies.
Let's start by configuring the data pipeline to get some tweets.
Python Libraries Stack and Set-Up
We’ll be using the following libraries:
- Tweepy - A convenient Python library for accessing the Twitter API
- NLTK - Natural Language Toolkit everything related to Language Processing. We are using it for text cleaning and tokenization
- transformers - Python library that provides thousands of pre-trained transformer models to perform tasks on texts such as classification, information extraction, question answering, summarization, translation, text generation, and more in over 100 languages. We will be using the ProsusAI/finbert model for financial sentiment analysis.
- wordcloud - Python module for creating word clouds
- plotly - Visualization library
- newscatcherapi - An easy-to-use Python library for fetching news articles programmatically.
The code for this article can be found here.
Let's start by installing all required libraries.
After that import all of them into your working environment.
- To work with the Twitter API, we need access tokens. For that, we have to apply for a developer account. Here’s the official documentation for getting started with the Twitter API.
Get Trends
Trend hijacking is a growth-hacking/marketing strategy in which the company or individual hops on a trending meme or ‘challenge’ to capitalize on the trend’s organic traffic.
To look for trends we use the trends_place() method that takes Where On Earth IDentifier (WOEID) as an argument id. WOEID is a unique 32-bit reference identifier that is used to refer to different locations on earth. For the purpose of this example, we’ll use New York’s WOEID (2459115).
You can use https://www.findmecity.com to find the WOEID for whatever location you want to look up the trends for.
- The prominent trends don’t exactly pop at us in this form. Let’s visualize the trends in the form of a word cloud.
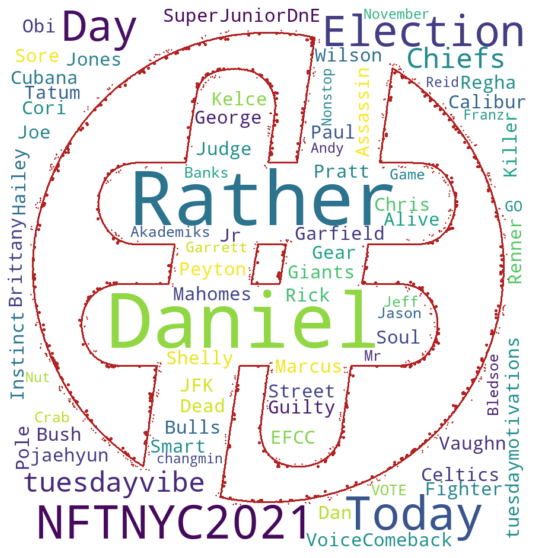
- Can you guess what day of the week the code was written?
- Get Tweets
- Trends aside, when we are concerned about the public sentiment around a product or company we often have to explicitly look up all tweets that mention it. We can search for tweets containing particular phrases using the Cursor object.
- Let's say we want to analyze the sentiment around the three big tech companies- Apple, Amazon, and Facebook, so we’ll fetch a thousand tweets for each. But before we do that, let’s fetch one tweet, print it, and familiarize ourselves with the structure of the tweet.
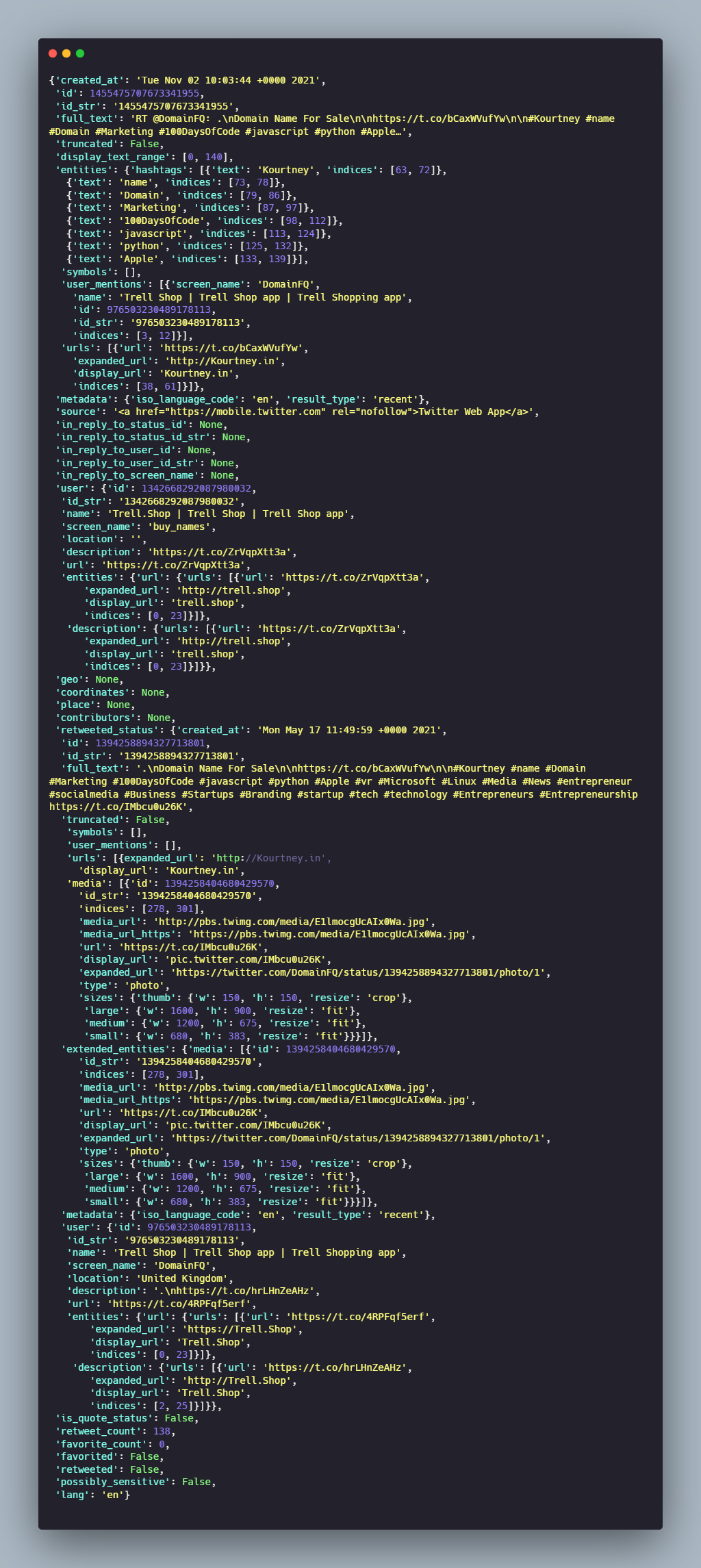
- There’s no lack of useful attributes in the tweet but we don’t need most of them for our purpose. Let's create a function that will help us extract relevant information for more than 1 tweet at scale.
- Now let’s use this function to extract 1000 tweets for each of the three big tech companies.
- Cleaning & Normalizing The Tweets
- The tweet text in its current form isn’t the most conducive to analysis. We need to clean it before applying our sentiment analysis models. Here are the normalization operations we will apply to the tweets:
- Delete @account_name at the beginning of retweets and any account mentions in the tweet text. This information isn’t needed for sentiment analysis and can be found in the ‘entities’ attribute of the tweets.
- Extract and store links in a different attribute and delete them from the tweet.
- Tokenize the remaining text.
- Remove punctuation and stopwords.
- Remove characters that are not alphabetic.
- There are no hard-and-fast rules for normalizing text, these are just the processes that will work best for our use case. Let’s create a function that does all these cleaning steps and use it on the tweets extracted above:
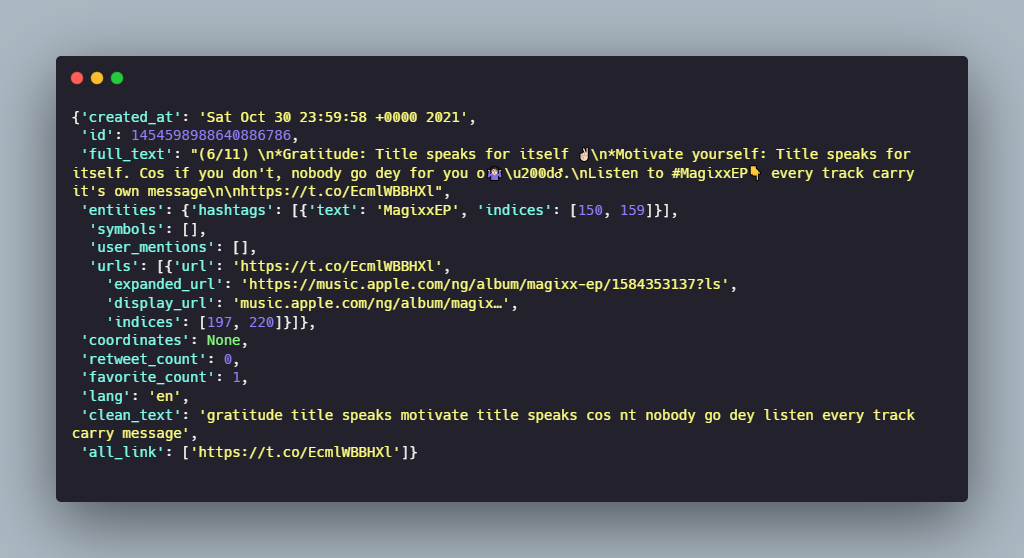
- Sentiment Analysis Using Transformers
- We can now do sentiment analysis on the cleaned tweet text. We’ll be using the FinBERT model for this. It is a transformer model trained on a large financial corpus. Let’s start by creating the sentiment analysis pipeline using the appropriate tokenizer and model. Then create a function for applying the sentiment analysis pipeline to each tweet.
Here is how one tweet looks like right now:
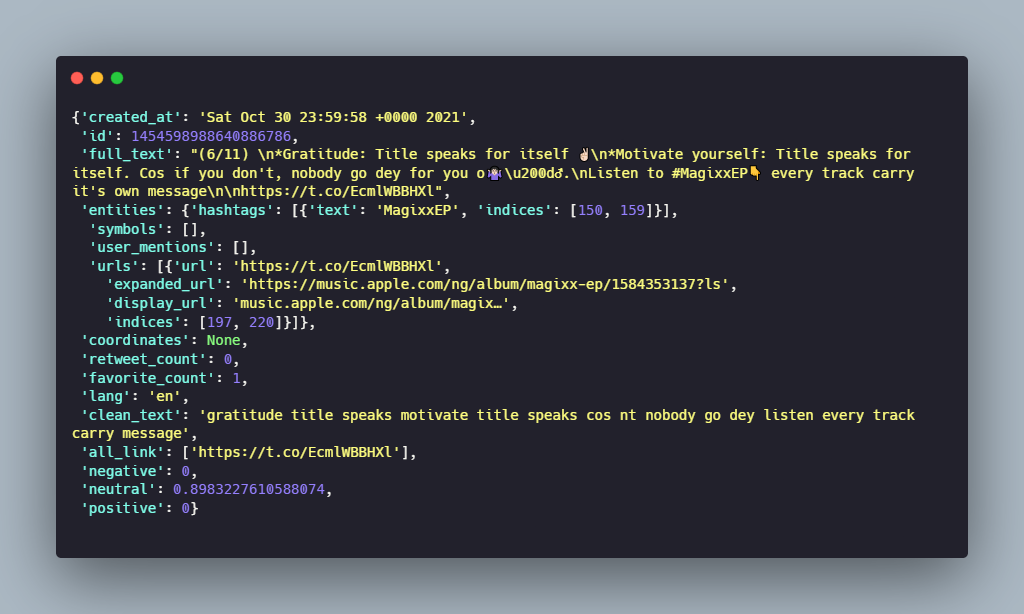
- Visualize The Results
- Viewing the sentiment of individual tweets doesn’t really help us establish the overall public sentiment. Visualizing the overall score for the companies will be much better.
- Convert the dictionaries into pandas Dataframes for ease of slicing/manipulating and then concatenate all together.
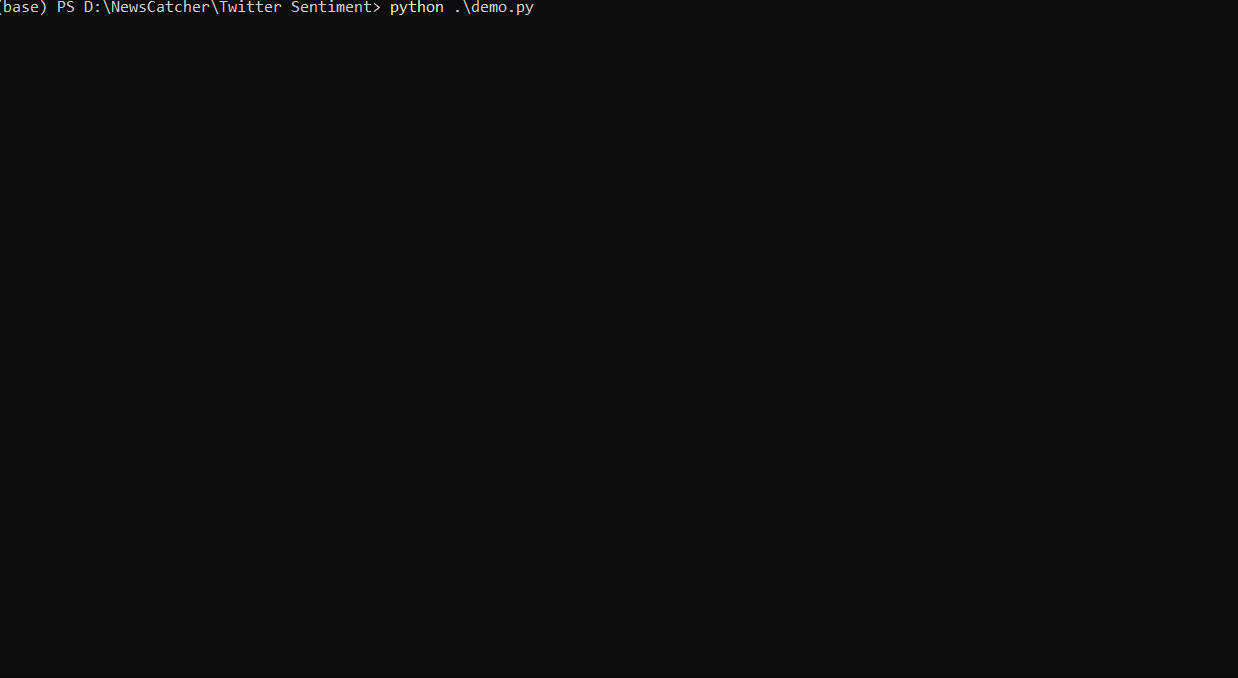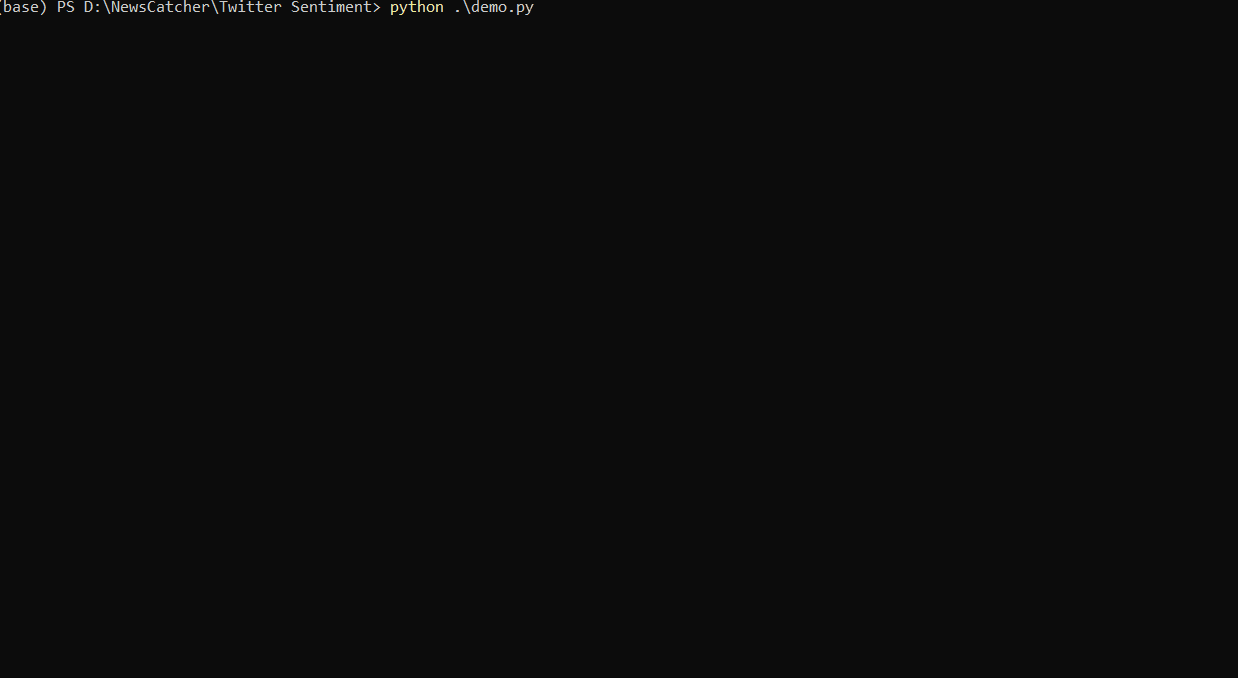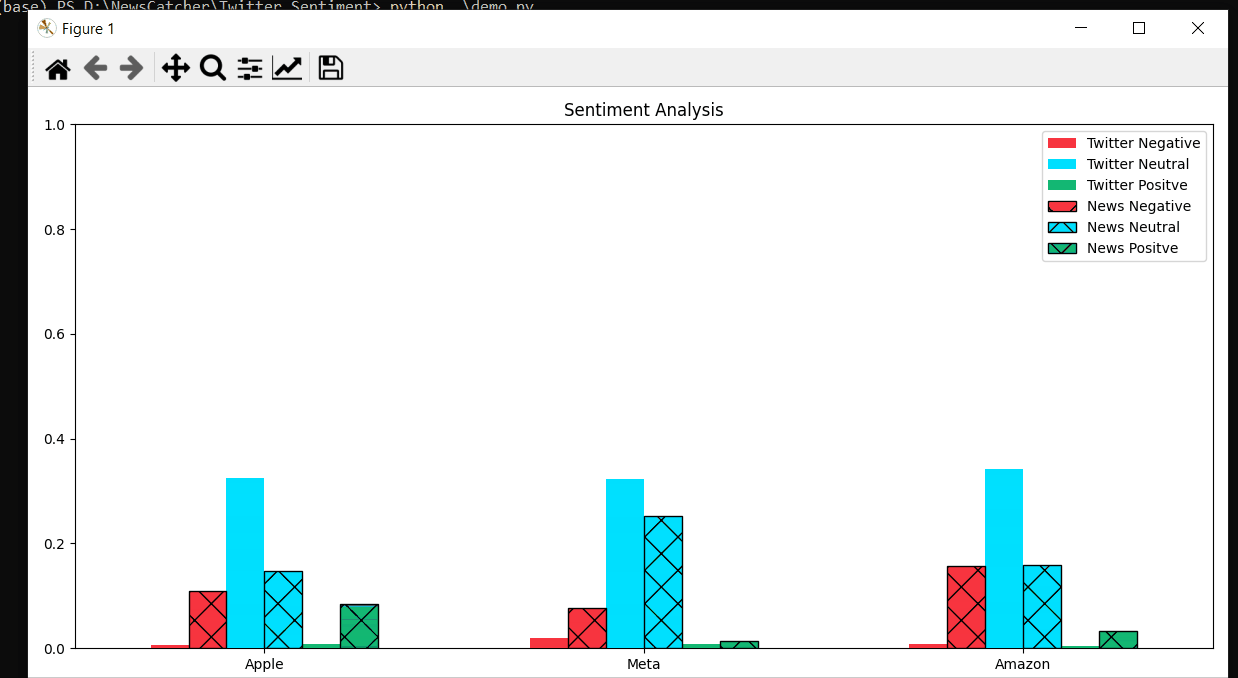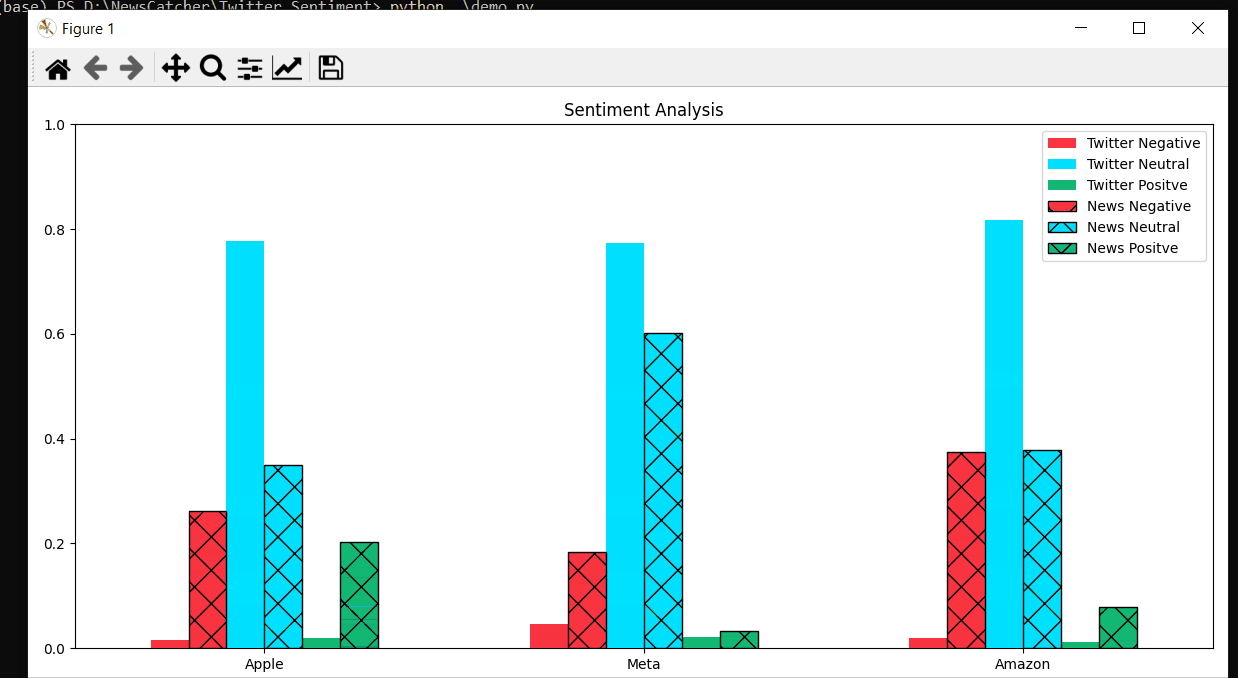
- That gives us:
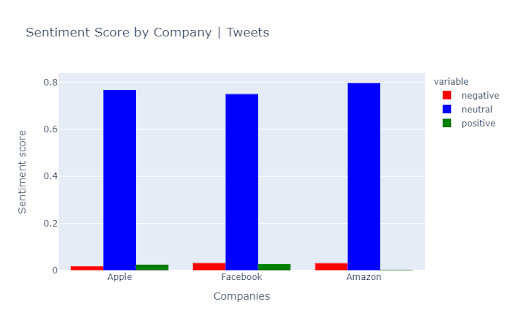
- as we can see, most parts of tweets do not contain any emotional attitude, they are simply neutral. We only extracted 1000 tweets for each company. Increasing the number of tweets could bring different results. But here, we can see the trend: Amazon has a greater number of negative tweets. When for Apple and Facebook positive and negative numbers of tweets are almost equal.
- News Sentiment Analysis With Python
- Another great source for gauging public sentiment can be news articles. Let’s try to do the same kind of analysis for the three companies but on news articles. We’ll be using the newscatcherapi package to fetch the news articles, to work with it you’ll need to get an API key from here.
- The news text is well-written and isn’t littered with things like mentions, hashtags, and special characters. So we can skip the cleaning step and move straight to sentiment analysis.
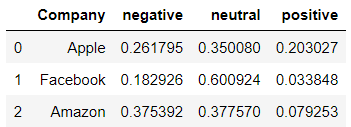
- And finally, visualize the scores.
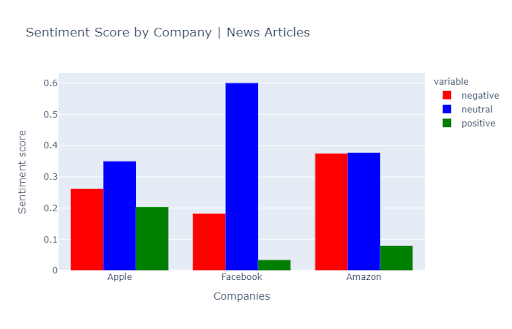
Conclusion
The goal of this article was to introduce you to a simplified process of Sentiment Analysis. Keep in mind that every analysis contains these steps:
- Data Extraction
- Data Cleaning
- Model Application
- Visualization
Our analysis was mainly focused on public sentiment towards 3 tech companies. It reveals the more sentimental/biased nature of news headlines. Where the majority of the tweets are neutral, news headlines seem to be predominantly negative. Should we be concerned 🤔

.png)







































