


















What is natural language processing? How does it work? Where is NLP used in the real world?
Our communications, both verbal and written, carry rich information. Even beyond what we are conveying explicitly, our tone, the selection of words add layers of meaning to the communication. as humans, we can understand these nuances, and often predict behavior using the information.
But there is an issue: one person alone can generate hundreds if not thousands of words in a single message or statement. And if we want to scale and analyze hundreds, thousands, or millions of people, the situation quickly becomes unmanageable. What if we used computers to automate this process? After all, computer processes can be scaled easily. Well, it’s not that simple. Communications fall under something called unstructured data, and computers are not good at working with unstructured data.
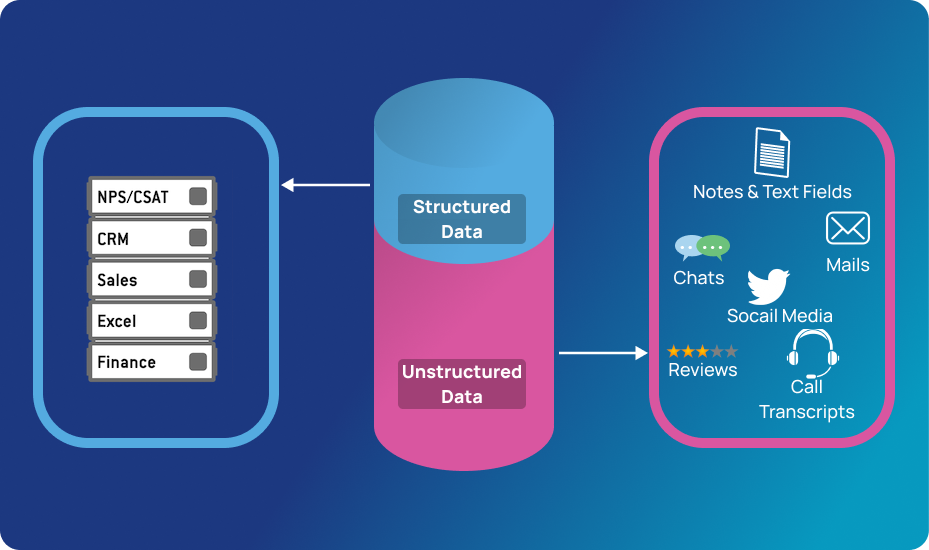
The text data generated from conversations, customer support tickets, online reviews, news articles, tweets are examples of unstructured data. It’s called unstructured because it doesn’t fit into the traditional row and column structure of databases, and it is messy and hard to manipulate. But thanks to advances in the field of artificial intelligence, computers have gotten better at making sense of unstructured data.
What Is Natural Language Processing (NLP)?

Natural Language Processing or NLP is a subfield of Artificial Intelligence that makes natural languages like English understandable for machines. NLP sits at the intersection of computer science, artificial intelligence, and computational linguistics. It enables computers to study the rules and structure of language, and create intelligent systems(built using machine learning/deep learning algorithms) that can automatically perform repetitive analytical and predictive tasks.
One of the main reasons natural language processing is so crucial to businesses is that it can be used to analyze large volumes of text data. Take sentiment analysis, for instance, which uses natural language processing to detect emotions in text. It is one of the most popular tasks in NLP, and it is often used by organizations to automatically assess customer sentiment on social media. Analyzing these social media interactions enables brands to detect urgent customer issues that they need to respond to, or just monitor general customer satisfaction.
NLP systems can process text in real-time, and apply the same criteria to your data, ensuring that the results are accurate and not riddled with inconsistencies.
How Does Natural Language Processing Work?
Natural language processing systems use syntactic and semantic analysis to break down human language into machine-readable chunks. The combination of the two enables computers to understand the grammatical structure of the sentences and the meaning of the words in the right context.
Any language can be defined as a set of valid sentences, but how do we assess the validity of sentences?
Syntax and semantics.
The syntax is the grammatical structure of the text, and semantics is the meaning being conveyed. Sentences that are syntactically correct, however, are not always semantically correct. For example, “dogs flow greatly” is grammatically valid (subject-verb - adverb) but it doesn't make any sense.
The syntactic analysis involves the parsing of the syntax of a text document and identifying the dependency relationships between words. Simply put, syntactic analysis basically assigns a semantic structure to text. This structure is often represented as a diagram called a parse tree.
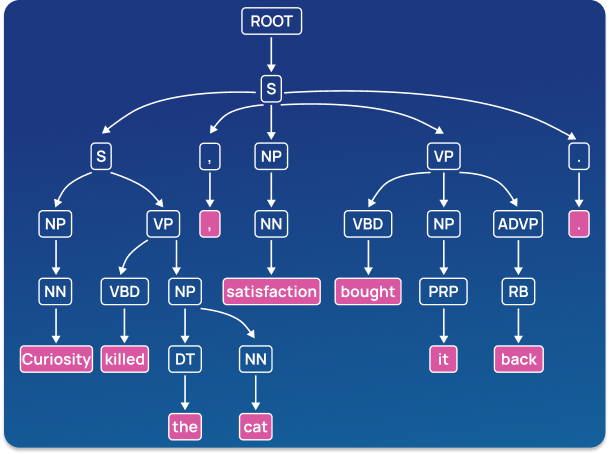
Consider a sentence with a subject and a predicate where the subject is a noun phrase and the predicate is a verb phrase. Take a look at the following sentence: “The cat (noun phrase) got wet (verb phrase), so, I (noun phrase) used (verb phrase) your towel (noun phrase) to dry it (verb phrase). ” Note how we can combine every noun phrase with a verb phrase. It’s important to repeat that a sentence can be syntactically correct but not make sense.
How we understand what someone says is a largely unconscious process relying on our intuition and our experiences of the language. In other words, how we perceive language is heavily based on the tone of the conversation and the context. But computers need a different approach.
Semantic analysis focuses on analyzing the meaning and interpretation of words, signs, and sentence structure. This enables computers to partly understand natural languages as humans do. I say partly because languages are vague and context-dependent, so words and phrases can take on multiple meanings. This makes semantics one of the most challenging areas in NLP and it's not fully solved yet.
Let’s take virtual assistants(Vas) as an example. The speech recognition tech has gotten very good and works almost flawlessly, but Vas still aren't proficient in natural language understanding. So your phone can understand what you say in the sense that you can dictate notes to it, but often it can’t understand what you mean by the sentences you say.
Also, some of the technologies out there only make you think they understand the meaning of a text. An approach based on keywords or statistics or even pure machine learning may be using a matching or frequency technique for clues as to what the text is “about.” These methods are limited because they are not looking at the real underlying meaning.
Here are a few fundamental NLP tasks data scientists need to perform before they can make sense of human language:
Tokenization
Tokenization is the first task in most natural language processing pipelines, it is used to break a string of words into semantically useful units called tokens. This can be done on the sentence level within a document, or on the word level within sentences. Usually, word tokens are separated by blank spaces, and sentence tokens by stops. You can also perform high-level tokenization for more intricate structures, like collocations i.e., words that often go together(e.g., Vice President).
Here’s an example of how word tokenization simplifies text:
Curiosity killed the cat, satisfaction bought it back. = "Curiosity", "killed", "the", "cat", ",", "satisfaction", "bought", "it", "back", ".".
Stemming & Lemmatization
When we speak or write, we tend to use inflected forms of a word (words in their different grammatical forms). To make these words easier for computers to understand, NLP uses lemmatization and stemming to change them back to their root form.

The word as it appears in the dictionary – its root form – is called a lemma. For example, the terms "is, are, am, were, and been,” are grouped under the lemma ‘be.’ So, if we apply this lemmatization to “Curiosity killed the cat, satisfaction bought it back.” The result will look something like this:
["Curiosity", "kill", "the", "cat", ",", "satisfaction", "buy", "it", "back", "."]
This example is useful to see how the lemmatization changes the sentence using its base form (e.g., the word "bought" was changed to "buy").
When we refer to stemming, the root form of a word is called a stem. Stemming "trims" words, so word stems may not always be semantically correct. For example, stemming the words “change”, “changing”, “changes”, and “changer” would result in the root form “chang”.
If we stem the above sentence using the Porter Stemmer algorithm, we get:
["Curios", "kill", "the", "cat", ",", "satisfact", "buy", "it", "back", "."]
While lemmatization is dictionary-based and chooses the appropriate lemma based on context, stemming operates on single words without considering the context. For example, in the sentence:
“This is better”
The word “better” is transformed into the word “good” by a lemmatizer but is unchanged by stemming. Although stemmers can lead to less-accurate results, they are easier to build and perform faster than lemmatizers. But lemmatizers are recommended if you're seeking more precise linguistic rules.
Stopword Removal

Removing stop words is an essential step in NLP text processing. It involves filtering out high-frequency words that add little or no semantic value to a sentence, for example, to, for, on, and, the, etc. You can even create custom lists of stopwords to include words that you want to ignore.
Let’s say you want to classify customer service tickets based on their topics. In this example: “Hello, I’m having trouble logging in with my new password”, it may be useful to remove stop words like “hello”, “I”, “am”, “with”, “my”, so you’re left with the words that help you understand the topic of the ticket: “trouble”, “logging in”, “new”, “password”.
Vectorization
Once you decided on the appropriate tokenization level, word or sentence, you need to create the vector embedding for the tokens. Computers only understand numbers so you need to decide on a vector representation. This can be something primitive based on word frequencies like Bag-of-Words or TF-IDF, or something more complex and contextual like Transformer embeddings.
Here's an example of what the simplest method for generating vector embeddings, one-hot encoding, looks like:

Natural Language Processing Algorithm
Once the text is cleaned and you have the appropriate vector embeddings, it’s time to move on to the next step: building an NLP algorithm (and training it) so it can interpret human language and perform specific tasks. There are two main approaches you can use here:
Rule-based approach: Rule-based systems rely on hand-crafted grammatical rules that need to be created by experts in linguistics, domain experts, or knowledge engineers. This was the earliest approach to crafting NLP algorithms, and it’s still used today in many applications.
Machine learning algorithms: Machine learning models, on the other hand, are based on statistical methods and learn to perform tasks after being fed examples (training data).
The biggest advantage of machine learning algorithms is their ability to learn on their own. You don’t need to define manual rules – instead, they learn from previous data to make predictions on their own, allowing for more flexibility.
Okay, so now we know the flow of the average NLP pipeline, but what do these systems actually do with the text? Let's take a look at the most common NLP tasks.
Natural Language Processing Tasks
Part-of-Speech Tagging
Part-of-speech tagging (abbreviated as PoS tagging) involves adding a part of speech category to each token within a text. Some common PoS tags are verb, adjective, noun, pronoun, conjunction, preposition, intersection, among others. In this case, the example above would look like this:

PoS tagging enables machines to identify the relationships between words and, therefore, understand the meaning of sentences.
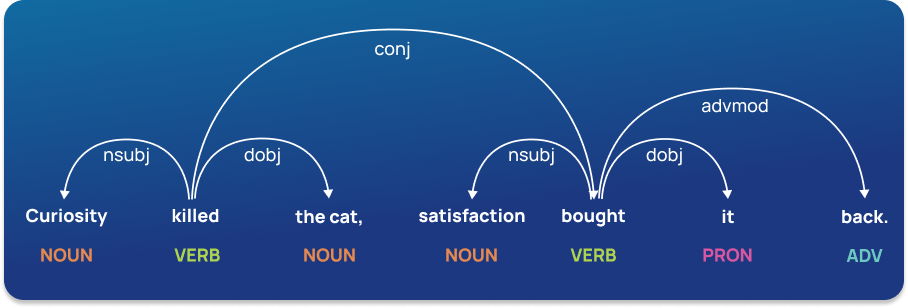
Dependency Parsing
Dependency grammar refers to the way the words in a sentence are connected. A dependency parser, therefore, analyzes how ‘head words’ are related and modified by other words to understand the syntactic structure of a sentence.
Named Entity Recognition (NER)
Named entity recognition is one of the most popular tasks in natural language processing and involves extracting entities from text documents. Entities can be names, places, organizations, email addresses, and more.

Another NLP task, relationship extraction takes this one step further and finds relationships between two nouns. For example, in the phrase “Lumiere lives in Nice,” a person (Lumiere) is related to a place (Nice) by the semantic category “lives in.”
Text Classification
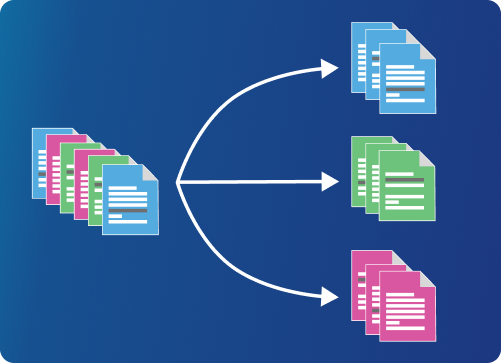
Text classification is the process of understanding the meaning of the unstructured text and organizing it into predefined classes (also called labels, or tags). One of the most popular text classification tasks is sentiment analysis, which aims to categorize unstructured text data by sentiment. Other common classification tasks include intent detection, topic modeling, and language detection.
Word Sense Disambiguation
Depending on their context, words can have different meanings. Take the word “book”, for example:

There are two main techniques that can be used for word sense disambiguation: knowledge-based (or dictionary approach) or supervised approach. The first one tries to infer meaning by observing the dictionary definitions of ambiguous terms within a text, while the latter is based on machine learning algorithms that learn from training data.
Ready to dive into some real-world applications of NLP?
Industry Applications Of NLP
News Aggregation
There are hundreds of thousands of news outlets, and visiting all these websites repeatedly to find out if new content has been added is a tedious, time-consuming process. News aggregation enables us to consolidate multiple websites into one page or feed that can be consumed easily.
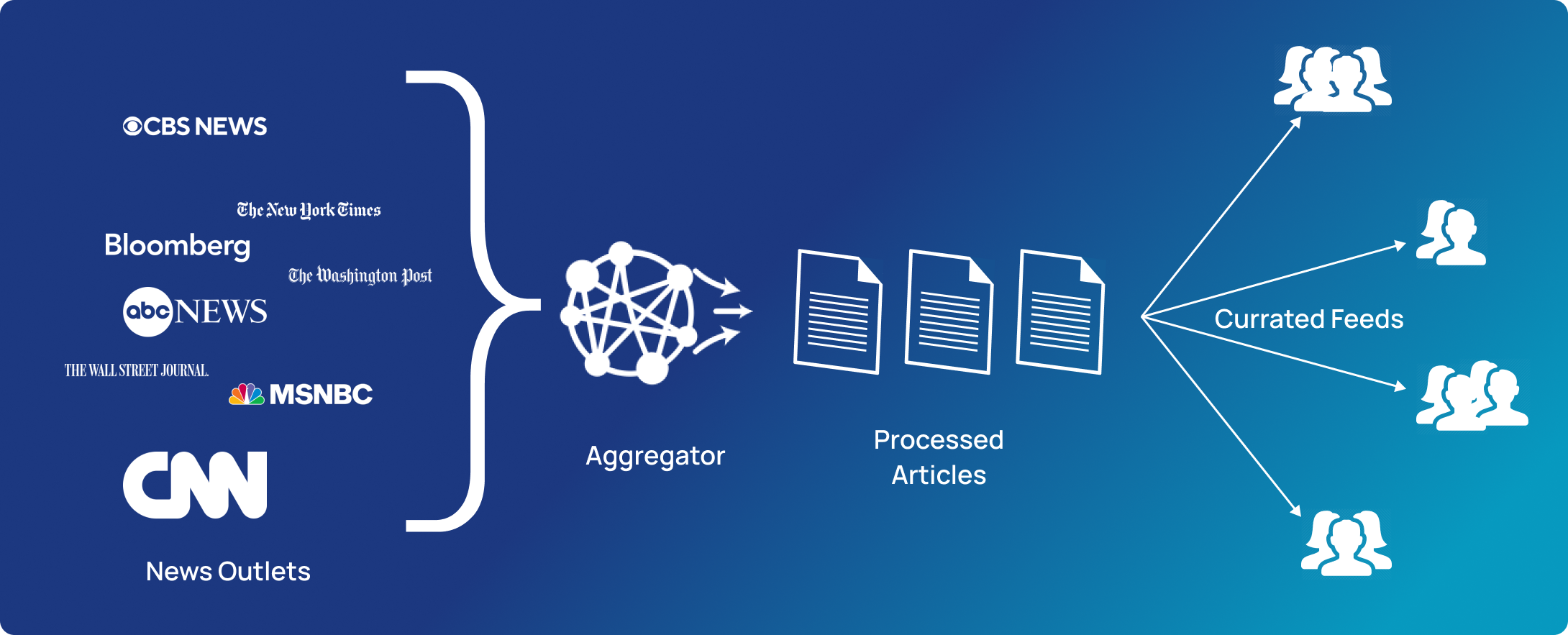
News aggregators go beyond simple scarping and consolidation of content, most of them allow you to create a curated feed. The basic approach for curation would be to manually select some new outlets and just view the content they publish. But this leaves a lot of room for improvement. Using NLP, you can create a news feed that shows you news related to certain entities or events, highlights trends and sentiment surrounding a product, business, or political candidate.
Social Media Monitoring
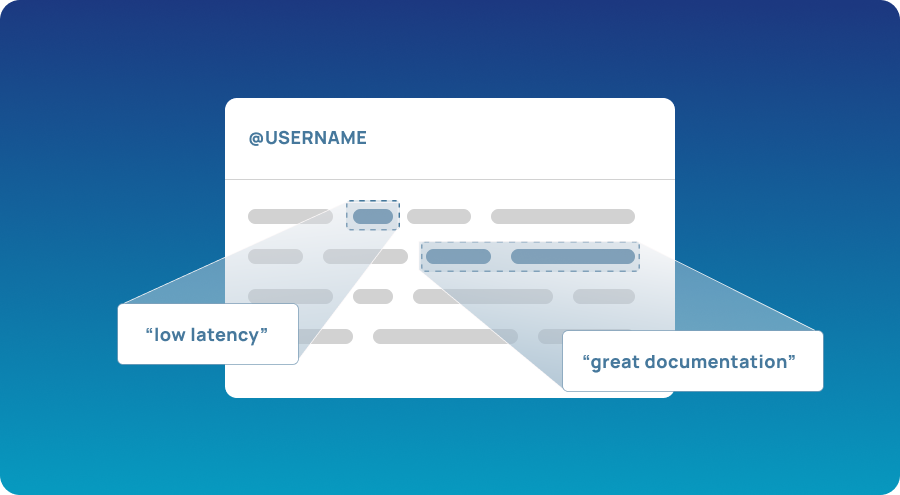
Most of the communication happens on social media these days, be it people reading and listening, or speaking and being heard. as a business, there’s a lot you can learn about how your customers feel by what they post/comment about and listen to.
But trying to keep track of countless posts and comment threads, and pulling meaningful insights can be quite the challenge. This is where NLP comes in handy. Using NLP techniques like sentiment analysis, you can keep an eye on what’s going on inside your customer base. You can also set up alerts that notify you of any issues customers are facing so you can deal with them as quickly they pop up.
Analytics For Marketing
A great way to keep tabs on your competition is to include their websites and blogs in your aggregators. From an SEO point-of-view, you can analyze your competitor’s content to find the keywords and content that have been most beneficial to them.

An excellent tool for marketers is the Share Of Voice (SOV) measurement. In simple terms, SOV measures how much of the content in the market your brand or business owns compared to others. This enables you to gauge how visible your business is and see how much of an impact your media strategies have.
Automated Customer Service
Customer service is an essential part of business, but it’s quite expensive in terms of both, time and money, especially for small organizations in their growth phase. Automating the process, or at least parts of it helps alleviate the pressure of hiring more customer support people.
Although chatbots might be the first thing that you think of, there are a number of other ways NLP enables the automation of customer service. NLP can be used to detect sentiment and keywords in direct communications like emails and phone calls, or social media posts. These communications can then either receive an automated response or be automatically assigned to relevant teams for a quick resolution.
This automatic routing can also be used to sort through manually created support tickets to ensure that the right queries get to the right team. Again, NLP is used to understand what the customer needs based on the language they’ve used in their ticket.
Content Filtering
Spam filters are probably the most well-known application of content filtering. 85% of the total email traffic is spam, so these filters are vital. Earlier these content filters were based on word frequency in documents but thanks to the advancements in NLP, the filters have become more sophisticated and can do so much more than just detect spam.
Take for instance your Gmail inbox, the emails are sorted into primary, social, promotions, and updates without manually configuring any filters. Behind all the filters is NLP: your emails are automatically parsed and analyzed using text classification and keyword extraction methods.
Similar filtering can be done for other forms of text content - filtering news articles based on their bias, screening internal memos based on the sensitivity of the information being conveyed.
Getting Started With NLP

Now that you have a decent idea about what natural language processing is and where it’s used, it might be a good idea to dive deeper into some topics that interest you. Want to learn more of the ideas and theories behind NLP? Take a look at the recommended courses and book. Want to skip that and learn by applying? Start by learning one of the many NLP tools mentioned below.
NLP libraries and tools
There are a lot of programming languages to choose from but Python is probably the programming language that enables you to perform NLP tasks in the easiest way possible. And even after you’ve narrowed down your vision to Python, there are a lot of libraries out there, I will only mention those that I consider most useful.
Natural Language Toolkit (NLTK)
NLTK is a Python library that allows many classic tasks of NLP and that makes available a large amount of necessary resources, such as corpus, grammars, ontologies, etc. It can be used in real cases but it is mainly used for didactic or research purposes.
To understand the main concepts in NLTK, you can start by reading the first chapter of the book Natural Language Processing with Python. If you prefer to watch videos, you can go through this awesome tutorial series by sentdex.
spaCy
In my opinion, spaCy is the best NLP framework of the moment. Reading the documentation is worth it to understand the key concepts used in NLP applications: token, document, corpus, pipeline, tagger, parser, etc. It is really fast and scales very well. And it is pretty easy to use, so you can give it a try if you want to, say, tokenize (i.e. segment a text into words) your first document.
Stanford CoreNLP
The Stanford NLP Group has made available several resources and tools for major NLP problems. In particular, the Stanford CoreNLP is a broad range integrated framework that has been a standard in the field for years. It is developed in Java, but they have some Python wrappers like Stanza. Where Stanford CoreNLP really shines is the multi-language support. Although spaCy supports more than 50 languages, it doesn’t have integrated models for a lot of them, yet.
Books And Courses To Learn NLP
Much like programming languages, there are way too many resources to start learning NLP. My suggestion? Choose a Python NLP library — NLTK or spaCy — and start with their corresponding resources.
Books-
1. Practical Natural Language Processing: A Comprehensive Guide to Building Real-World NLP Systems
2. Natural Language Processing with Python(NLTK Book)
4. Natural Language Processing in Action: Understanding, analyzing, and generating text with Python
5. Deep Learning for Coders with fastai and PyTorch: AI Applications Without a PhD
Courses-
1. Natural Language Processing Specialization
3. Data Science: Natural Language Processing (NLP) in Python




.png)






































