


















What is text classification? How does do text classifiers work? How can you train your own news classification models?
There’s an enormous amount of text out there, and more and more of it is generated every day in the form of emails, social media posts, chats, websites, and articles. All these text documents are rich sources of information. But because of the unstructured nature of the text, understanding and analyzing it is difficult and time-consuming. as a result, most companies are not able to leverage this invaluable source of information. This is where Natural Language Processing (NLP) methods like text classification come in.
What Is Text Classification?
Text classification, also known as text categorization or text tagging, is the process of assigning a text document to one or more categories or classes. It enables organizations to automatically structure all types of relevant text in a quick and inexpensive way. By classifying their text data, organizations can get a quick overview of the trends and also narrow down sections for further analysis.
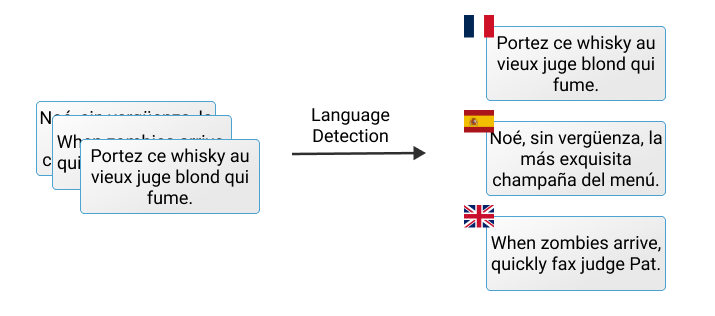
Let’s say you are hired by an organization to help them sort through their customer reviews. First things first, if the organization has a global customer base and there are reviews written in multiple languages, dividing them based on their language will help with downstream tasks.
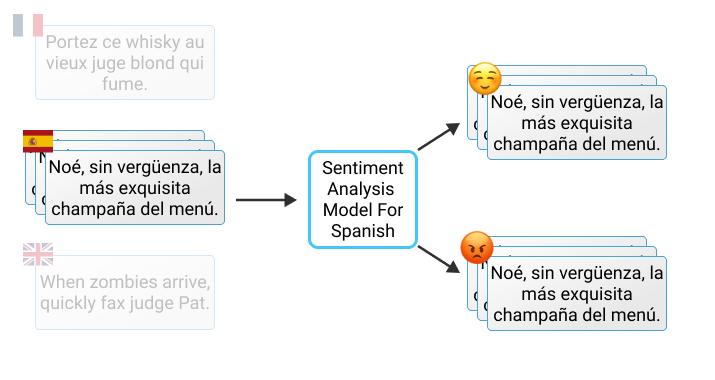
as uplifting and fulfilling as positive reviews are, they rarely contain any urgent issues that need to be addressed immediately. So, it might be a good idea to perform sentiment analysis and classify the reviews as positive and negative. Here your previous language classification will come in handy for making language-specific sentiment analysis models.
Once you have the negative reviews, you can further categorize them by feature/product mentioned. This will enable different teams to easily find relevant reviews and figure out what they’re doing wrong or what improvements need to be made.
How Does Text Classification Work?
There are two broad ways of performing text classification:
- Manual
- Automatic
Manual text classification involves a human annotator, who reads through the contents of the text documents and tags them. Now you might think that this method only causes problems when you’re working with large amounts of text. But you would be wrong to think so, here are two reasons:
Real-Time Analysis
as a side effect of being slow, manual classification hinders an organization’s ability to quickly identify and respond to critical situations. For instance, let’s say a cloud provider or an API goes down, if a person is sequentially going through the customer support tickets, it might take the organization a while to realize that their services are down.
Consistency
Humans are imperfect beings even on their best days. They’re prone to making mistakes due to factors like lack of sleep, boredom, distractions, etc. These can cause inconsistent classifications. For critical applications, these lapses can cost the organization thousands of dollars.
And beyond these disadvantages, human hours cost considerably more than running a Python script on a cloud server. So performing automatic text classification by applying natural language processing and other AI techniques is the best choice for most cases. Automatic classification is faster and more cost-effective. And on top of that, once a text classification model is trained to satisfactory specifications, it performs consistently.
There are many ways to automatically classify text documents, but all the methods can be classified into three types:
- Rule-based methods
- Machine learning-based methods
- Hybrid methods
Rule-based Methods
Rule-based methods use a set of manually created linguistic rules to classify text. These rules consist of a pattern or a set of patterns for each of the categories. A very simple approach could be to classify documents based on the occurrences of category-specific words.
Say that you want to classify news articles into two classes: Business and Science. To do this you’ll need to create two lists of words that categorize each class. For instance, you could choose names of organizations like Goldman Sachs, Morgan Stanley, Apple, etc. for the business class, and for the science class, you could choose words like NasA, scientist, researchers, etc.
Now, when you want to classify a news article, the rule-based classifier will count the number of business-related words and science-related words. If the number of business-related words is greater than science-related words then the article will be classified as Business and vice versa.

For example, the rule-based classifier will classify the news headline “
International Space Station: How NasA Plans To Destroy It” as science because there is one science-related word - “NasA” and no business-related words.
The biggest advantage of using rule-based systems is that there easy to understand by laymen. So once a bare-bones system is created, it can be incrementally improved over time. But the other side of this advantage is that the developers need deep knowledge of the domain to create the rules. Moreover, rule-based classification methods don’t scale well as adding new rules without proper testing can affect the results of older rules.
Machine Learning-Based Methods
Instead of defining the rules manually, you can choose a machine learning-based method that automatically learns the rules using past observations. Machine learning-based classifiers use labeled examples as training data to learn associations between words/phrases and the labels, i.e., the categories.
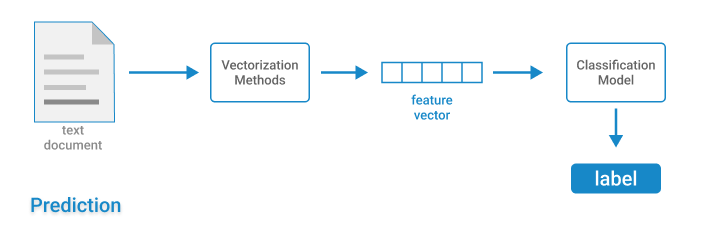
Now, that sounds easy enough to tackle, but there’s one problem you need to solve before you can train your machine learning classifier. Feature extraction. You see, computers don’t understand the text as we do, they only understand numbers, 0s & 1s. In the case of computer vision problems, the images are internally stored in the form of numbers representing the values of the individual pixels.
But that isn’t the case for text. So, the first step for training an NLP classifier is to transform the text into a numerical vector representation. One of the most commonly used text embedding methods is bag of words. It creates a vector that counts the occurrences of each word in a predefined dictionary.
Let's say you define the dictionary as: “(What, a, sunny, serene, beautiful, day, night)”, and you want to create the vector embedding of the sentence “What a serene night”. You would end up with the following vector representation for the sentence: (1, 1, 0, 1, 0, 0, 1).
After you have generated the vector representation of all the labeled text documents, you can use them to train a classifier. The vector representation of text documents is passed to the classifier with their correct categories. The model learns the associations between different linguistic features in the text and the categories:

Once the model has been trained up to the required performance standards, it can be used to make accurate predictions. The same feature extraction method is used to create the vector representation of the new text documents. The classification model uses these feature vectors to predict the categories of the documents.
Machine learning-based text classification methods are generally more accurate than rule-based classifiers. Besides that, machine learning classifiers are easier to scale as you can simply add new training examples to update the model. The only problem with machine learning classifiers is that they are hard to understand and debug. So if something goes wrong, it can be hard to figure out what caused the issue.
Hybrid Methods
Hybrid text classification methods combine the best of both worlds. They combine the generalization ability of the machine learning classifier with the easy-to-understand and tweak rule-based methods. They can learn complex rules thanks to the machine learning model, and any conflicting classifications or erratic behavior can be fixed using rules.
Take for instance the task of classifying financial news articles based on their industrial sectors such as pharma, finance, automotive, mining, etc. To do this you can create a hybrid system. First, train a named entity recognition model that extracts company names from the news articles. Then, create a list of the companies in each sector. And that's it, using these two things you can create a competent classifier.
Classifying News Headlines With Transformers & scikit-learn
Firstly, install spaCy wrapper for sentence transformers, spacy-sentence-bert, and the scikit-learn module.
And get the data here.
You'll be working with some of our old Google News data dumps. The news data is stored in the JSONL format. Normally you can load JSONL files into a DataFrame using the read_json method with the lines=True argument, but our data is structured a bit weirdly.
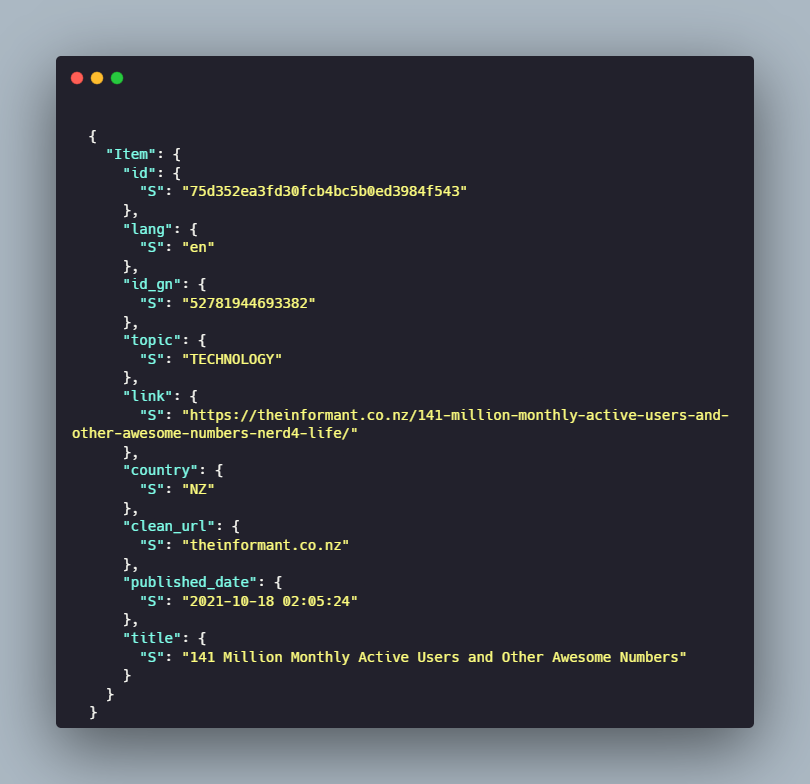
Each of the individual entries is stored within an Object (enclosed within {'item':}). So, if you try to load it straight away with the read_json method it will load all of it as one column.
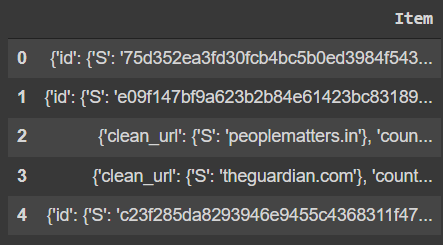
To fix this, you can read the file like a normal text file and use the json.loads method to create a list of dictionaries.
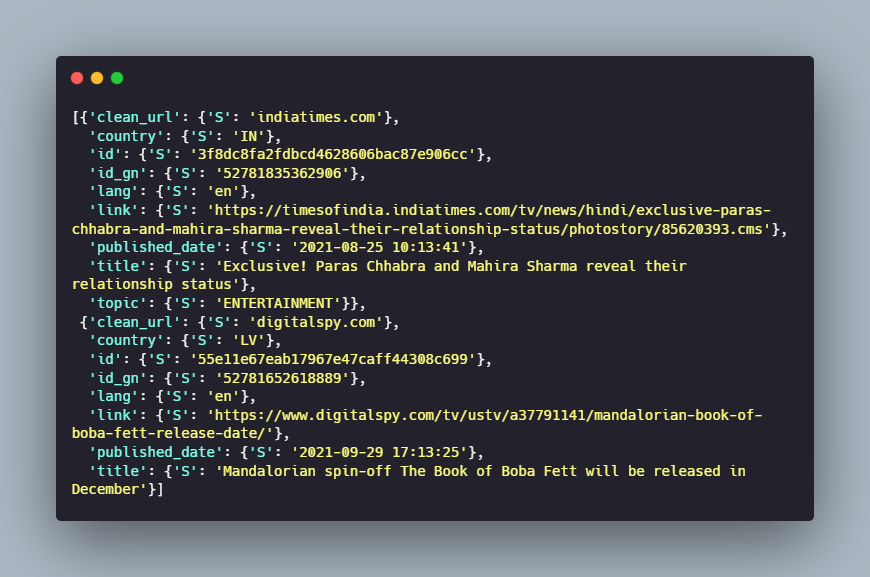
There is still an issue to deal with 😬. The value of the attributes for each headline is stored inside its own object. Fret not, you can quickly fix it with some more dictionary manipulation.
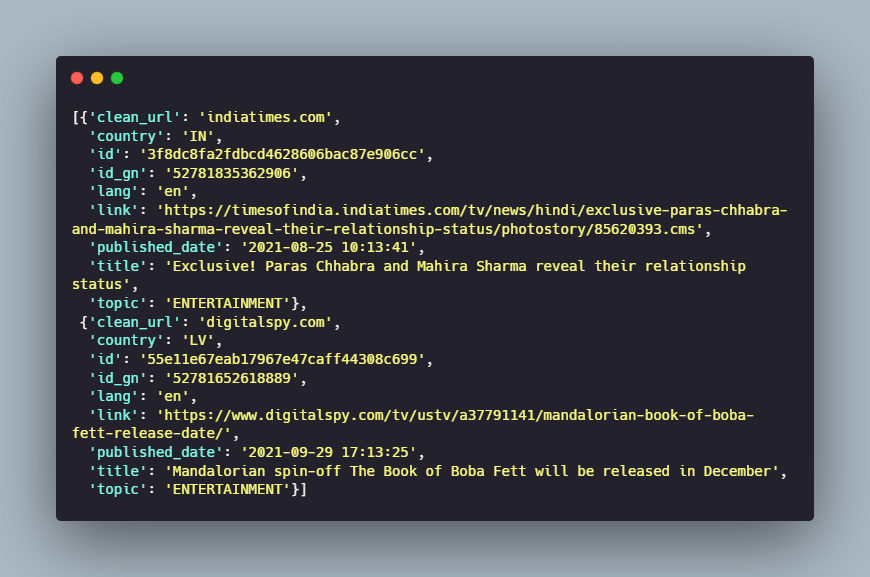
Now you can create a DataFrame out of the news data.
Let's take a look at all the topic labels.
You don't really need the other attributes like country, lang, or cleaned_url. And the topic labels-'WORLD' and 'NATION' are not very informative as their definition is very loose. So, you can drop them off.
Let's check for missing values and drop incomplete entries.
Next, you should take a look at how many training examples we have for each category.
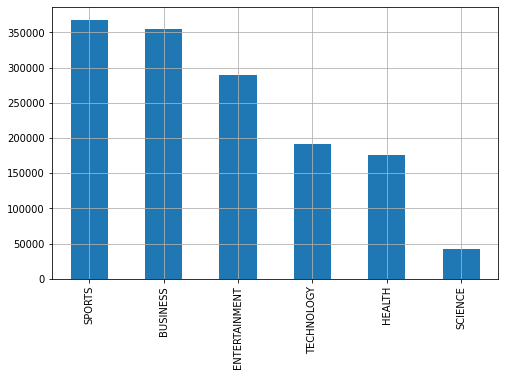
More than 350000 articles for the two biggest categories and even the small group has about 40000 examples!
What about the distribution of headline lengths?
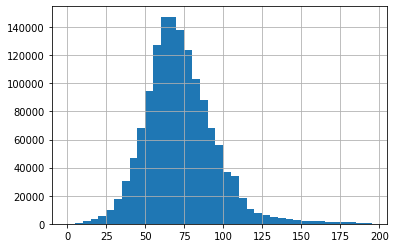
Looks "normal". Get it?
Jokes aside, as you're going to use the state-of-the-art BERT transformer model to create the vector representations, I recommend that you train the models with a subset of the available dataset.
Now you can load the BERT sentence transformer and create the vector embedding for the headlines.
Let's split the data into training and testing sets.
And finally, you can train your choice of machine learning classifier.
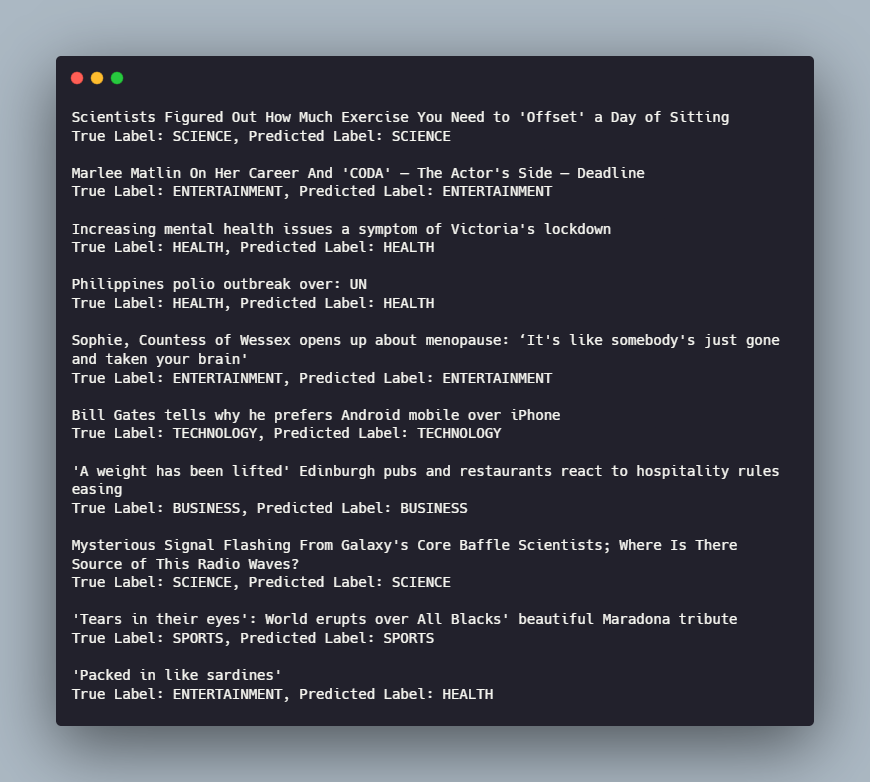
The Support Vector Classifier(SVM) comes out on top. You can use this to predict the topic of new news headlines.
Let's try it out on a bunch of news headlines from Google News:
Conclusion
There you have it. You now know what text classification is, how it works, and how you can train your own machine learning text classifiers. But hey, what about neural networks? That's a good question! The thing is, as good as neural networks are they are not really necessary for this task. Both SVMs and NNs can approximate non-linear decision boundaries, and they both achieve comparable results on the same dataset. Neural networks can pull ahead in performance but they need a lot more computational power, training data, and time.
On the other hand, support vector machines can reliably identify the decision boundary based on the sole support vectors. Therefore, you can train an SVM classifier with a small subset of the data you would need to train a neural network that achieves similar performance. If, however, any marginal increase in performance is beneficial for your application feel free to go with neural networks.




.png)






































