/v2/search endpoint, our news API returns
some key information. For example, an API call about “Tesla” for the last week
total_hits tells you how many articles are found.
One API search can yield a maximum of 10,000 hits.
total_hits, chances are that there are more than
10,000 news articles for your query. The above Telsa example API call actually
matches 25,290 articles. To get all of these results, you have two choices:
- Manually divide your search query into smaller time periods and then combine the results.
- Use the
get_search_all_articlesmethod from our Python SDK to automatically divide your query.
Manually divide your news search query
The idea is simple, break down your queries into smaller time periods so our API can accommodate all the matches. Continuing the Tesla search example, to get all the 25,290 news articles you’ll need to make a number of smaller search requests. Although technically you should be able to fetch all the results in just three API calls, that’s not advisable because you don’t know how many articles were published in a time period without making additional API calls.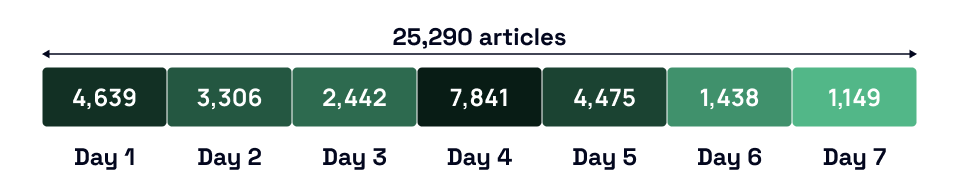
The distribution of Telsa relevant news articles throughout the week
Use get_search_all_articles method
You can also automate this process of dividing your queries with the
get_search_all_articles method. It takes your query and based on the by
parameter divides it into a bunch of sub-queries. It then returns the
combination of all their results.
To get all the articles for the Telsa query you can simply:
by parameter accepts four values: 'hour', 'day', 'week', and
'months'. And it is set to 'week' by default.