


















We are a team of 2 data engineers. From February to March 2020 we dedicated most of our spare time building an API that allows you to search for the news articles’ data.
This article was originally posted here.
This article got published soon after we delivered our beta. It was a long time ago. as of today, we have our stable production version up and running. Of course, our today's solution architecture differs from the one described here. Still, we find it important to share our path.
-Artem, CEO
Within 60 days we:
- iterated our architecture design 3 times
- released Python package which got us 800+ stars on GitHub
- received 200+ sign-ups for the beta
- delivered our Minimum Viable Product
In this article:
- Part I. Product
- Part II. Plan & Requirements
- Part III. Solution Architecture
- Part IV. Post Beta
- Conclusion
We are a team of 2 data engineers. From February to March 2020 we dedicated most of our spare time building an API that allows you to search for the news articles’ data.
It is like querying Google News archives with a simple line of code.
We had little to no prior experience of using AWS or delivering successful end-to-end solutions. Still, the right planning, asking for help, and investing some time to find the right tools made it possible.
Principles that we followed
On the business side:
- Use external tools as much as you could
- Deliver as fast as possible so you get the users’ feedback asAP
- Users first. They should decide what is important and what is not
On the technical side:
- Minimize the use of the servers that you have to run yourself
- Do not write the code if it is already written
- Performance is important only if it makes it impossible for customers to use your solution
- ask for help
Part I. Product

Photo by José Martín Ramírez C on Unsplash
Problem
Most of us read the news. It is easy to follow the things that interest us when we consume the news for personal interest.
Many businesses also have to be constantly updated on what is going on around the globe. The classical example is financial institutions. They use alternative data to identify the risks arising from non-financial activities.
Political, cultural, and social events can trigger another chain of events that may reshape certain financial markets.
Of course, you can google any keyword or topic and find the most relevant news results. But, let’s say you are a trader who wants to be updated on the latest news on each company of your portfolio. Hourly.
Or, you have to analyze how many times a person/company/event X got mentioned over the past month.
Or, you want to show the latest news on a particular topic to the users of your service.
At some point, manual work becomes either impossible or too expensive. Thousands of news articles need to be analyzed. You have to automate the process if you want to scale it.
Solution
Newscatcher API is a JSON API that lets you search for news data. For example, you would like to get the list of all articles about Apple Inc. that got published over the last day.
For each data record, you get:
- relevance score (how well the article match the searching criteria)
- URL
- published date and time
- title
- summary
- language of article
- global rank of the website
We collect and, more importantly, normalize news articles data from thousands of news websites.
Is it Data-as-a-Service?
Auren Hoffman’s “Data-as-A-Service Bible” is the must-read for anyone who wants to understand what is data business.
According to Auren’s vision, there are 3 pillars of data business:
- Data Acquisition — we have to collect the news from thousands of different online news publishers
- Data Transformation — we have to normalize our data and store it so that it can be consumed by data delivery processes
- Data Delivery — we have to make it possible for clients to consume our data (API, for example)
Daas is selling you the materials, not the solution itself. You have to adapt the data to your needs to extract the value. So, the potential clients pool is decreased to those who have the data team as a resource. But, those clients with developers can tune data products exactly as they need.
Daas vs Saas
When you are hungry you have 2 main options.
The first one is to order some food from a restaurant or go to a restaurant. For example, you order pizza for 20$.
Another option is to go to the grocery store, buy all the ingredients for 8$, and cook yourself.
The drawback of cooking your own pizza is that you have to spend your time. Plus, you need to have some skills. But, it is cheaper (if you do not charge for your time), and you can customize it as much as you want.
Pizza from the restaurant usually cannot be customized.
The pizzeria is an example of Saas because it gives you the final product. The grocery store is an example of Daas because it gives you the resources to bake your own pizza.
What is Beta?
Beta is how you could:
- validate your idea,
- reveal the major technical issues
- collect the feedback on what are the most important features that users need
Usually, you do not charge for it, so it does not have to be perfect.
Why release a beta and not something final?
Well, you have to be really good at what you are doing and perfectly know your audience to be able to release “something of value” on the very first try. So spending a bit more time should payout at the end.
For us, it was also about validating our architecture. We had to see how different components stick together.
Beta = Minimum Viable Product
I am not sure if that is always true but should be for most cases. You leave only the functionality without which the product cannot survive.
Everything unnecessary goes to the Post-MVP task list.
Part II. Plan & Requirements

Photo by Lennart Jönsson on Unsplash
Beta version requirements
The user passes the word/phrase, API returns a bunch of articles about the searched topic. That simple.
It should be no longer than 3–5 seconds to receive the response from API.
We also added some filters because it was easy to do.
Any feature that required more than one hour to be developed got ditched.
How to build a news API?
In simple words, we have to get articles from news websites like nytimes.com, theverge.com, etc. The ultimate goal would be to get it from any existing news website.
Then, data normalization & deduplication — the most important part. Each article is a data point — it has a set of variables, such as title, published date, author, etc.
For example, the date and time when an article got published should be of one timezone in our final data source. Otherwise, querying data by time will not make any sense.
Finally, after we collect and normalize, we should store the data somewhere. More to that, it should be easy to retrieve the data. In our case, we rely a lot on a searching feature.
Get the articles. Data Collection
Before I start explaining the architecture design I should explain how we are going to collect news articles’ data.
The first thought might be to set up web scrapers for each website. Web scraping is well developed — there are plenty of open-source libraries making web scraping easy.
But, each website has its own structure. Even though there are some amazing libraries that help you structure the data from news articles, it will not work for 100% of the sources.
Making thousands of web crawlers that can avoid being banned is expensive and time-consuming.
In a perfect world, I would have an API to retrieve the latest news from each news data provider. Plus, each API would be of the same design.
But there is no such APIs. However, another method to get news data exists. And, it is already normalized. It is called RSS.
According to Wikipedia, RSS is a web feed that allows users and applications to access updates to websites in a standardized, computer-readable format.
For news websites, updates to websites are new news articles. Almost every news website has it.
RSS is already normalized. Kind of. You need a little bit of extra work to extract the main fields out of it.

Main RSS of nytimes.com
Part III. Solution Architecture
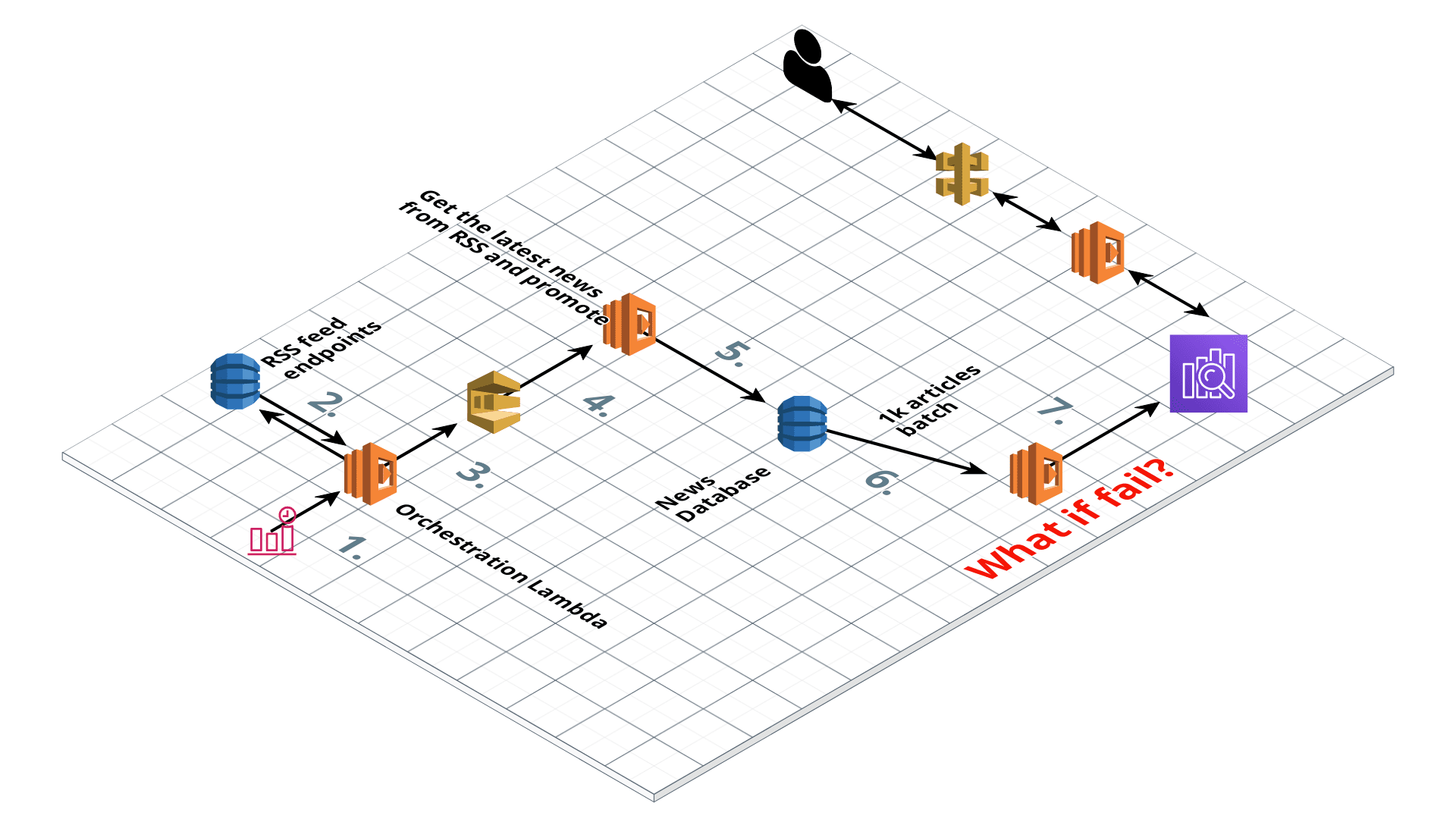
newscatcherapi.com AWS architecture diagram for beta
It takes 7 steps to deliver collected and normalized data to our final data storage — Elasticsearch:
- CloudWatch Event triggers Lambda
- Lambda gets the RSS feeds URLs from DynamoDB
- The same Lambda sends all those RSS URLs to SQS
- Each RSS endpoint from SQS is picked-up by Lambda that reads and normalizes the feed
- News articles data is inserted into DynamoDB
- DDB streams collect up to X newly inserted records and send it to Lambda
- Lambda inserts new records into Elasticseearch
Step 1. CloudWatch Event triggers the “orchestration” lambda
AWS Lambda is a serverless Function-as-a-service tool that runs your code in response to an event. You do not have to maintain servers. You pay only for the time that function is executed.
CloudWatch Event is an AWS implementation of a [cron job].
You can set up CloudWatch Event to trigger your Lambda each X minutes, hours, days, etc.
Step 2. “Orchestration” lambda gets the RSS feeds URLs from DynamoDB
DynamoDB table contains all the RSS feeds that we use to update our news database
DynamoDB is a fully managed No-SQL database from AWS. Same as AWS Lambda you do not have to manage the hardware or software behind it. You use it as an out-of-a-box solution to store your data.
Step 3. “Orchestration” lambda sends all those RSS URLs to SQS
Now you have a list of all the RSS feeds that have to be processed.
There are thousands of them so making a loop to process each one is not an option.
Let’s assume we have another Lambda function that can read and normalize the RSS. AWS Lambda allows you to make hundreds of parallel calls. Hence, you can think of calling many other Lambdas from your current Lambda.
Such an approach should work, however, it makes your process complex and prone to failure.
So you need something in the middle.
Simple Queue Service is a fully managed queue service by AWS.
Instead of triggering RSS processing Lambdas from our “orchestration” Lambda, we will send all the RSS endpoints to SQS as messages. Then, new messages from SQS can trigger RSS processing Lambda.
By adding the SQS layer we made it much easier to check the success on each RSS endpoint processing. If one of the Lambdas fails it does not disrupt any other Lambdas that process other RSS feeds.
Step 4. Each RSS endpoint from SQS is picked-up by Lambda that reads and normalizes the feed
My favorite feature of AWS Lambda is that you do not pay more for being able to execute many Lambdas simultaneously. It makes Lambda a useful tool when you do not know your workload ahead or want to be sure that your system will not crush when it receives more loads.
This Lambda is a Python function that takes RSS URL as an input and returns structured data (title, published DateTime, authors, article URL, etc.)
Now, when we extracted and normalized news articles’ data from each RSS feed it has to be stored.
Step 5. News articles data is inserted into DynamoDB
Before sending data to the Elasticsearch cluster we put it to DynamoDB. The main reason is that Elasticsearch does fail. Elasticsearch is great for many things (that we will discuss later) but Elasticsearch cannot be your main data storage.
Deduplication. Each RSS feed is updated once in a while. It adds some more articles to the feed. For example, the RSS feed of news website X always contains 100 articles. The feed is updated once every hour. If during this hour there were 10 new articles then they will appear on the top. While the oldest 10 articles will be removed. The other 90 articles will be the same as an hour ago. Hence, all those 90 articles are duplicates in our database.
And we have thousands of such feeds.
So it would be nice if we could verify if each ID (whatever it is) already exists in our database.
The trick is to make sure that we have a consistent ID key for each news article. We are MD5ing title+url of each article. Then when we insert this data to DynamoDB only new IDs are allowed (check attribute_not_exists settings of DynamoDB for that).
Hence, we do not have to deduplicate the data ourselves.
Step 6. DDB streams collect up to X newly inserted records and send them to Lambda
Now, we have to send new data from DynamoDB to the Elascticsearch cluster.
We made a trigger on DynamoDB inserts. Each time any data is inserted into DynamoDB it is picked up by Lambda that sends this new data into the Elasticsearch cluster.
Loading data into DynamoDB we significantly reduce the load on ES because it will receive a much lower amount of new data. Plus, DynamoDB is our main source of data.
Step 7. Lambda inserts new records into Elasticsearch
DynamoDB takes all the heavy work on making sure we do not have duplicates in our database. Only newly inserted records go to the Elasticsearch cluster.
You can set your Lambda to wait for new X records or Y minutes and take multiple records at once. This way you will have fewer transactions, plus you can take advantage of Elasticsearch bulk inserts.
Why Elasticsearch?
Because it is the best way to work with full-text search.
Elasticsearch is complex, you can tweak almost anything. Knowing well the purpose and use of your data allows you to optimize your cluster for the best performance.
Nevertheless, for the beta purpose, we used the default setting almost everywhere.
Data Delivery/API
Up to this point, we made sure our Elasticsearch cluster gets updated with new data. Now, we have to provide users with a tool to interact with our data. We have chosen to make it a RESTful API.
My favorite combination is to do it with API Gateway + Lambda.
From the AWS page:
API Gateway handles all the tasks involved in accepting and processing up to hundreds of thousands of concurrent API calls, including traffic management, CORS support, authorization and access control, throttling, monitoring, and API version management.
So API Gateway is responsible to manage API requests. We still have to implement the logic level. Each API call will be processed by the Lambda function.
Lambda itself is written with a micro web framework called Flask.
The task of this Lambda is to parse the parameters that users pass (such as the phrase that they want to find the articles on). Then, it queries our Elasticsearch cluster. Finally, it composes a clean JSON response object that will be sent to the user.
Apart from Flask, we used elasticsearch-dsl-py package that helps with writing and running queries against Elasticsearch.
I recommend deploying API Lambdas with Zappa:
Zappa makes it super easy to build and deploy server-less, event-driven Python applications (including, but not limited to, WSGI web apps) on AWS Lambda + API Gateway. Think of it as “serverless” web hosting for your Python apps. That means infinite scaling, zero downtime, zero maintenance — and at a fraction of the cost of your current deployments!
Deploying your API with Lambda is most convenient when you are not sure how many calls you will have to serve.
More to that, if you have 0 calls, you pay 0.
Part IV. Post Beta
Initial (post-beta) release plan
In addition to everything we achieved for the beta:
- filter by language
- correct text analyzer for 6–10 most common languages
- exact match search
- must include/exclude a phrase
- filter by country
- top-news per country endpoint
- filter by topic (sport, business, entertainment, etc.)
- pagination
We will have a lot of work optimizing our Elasticsearch cluster. The biggest change is to correctly analyze text fields depending on the language.
The point is to make search aware of the language that users want. For example, the default Elasticsearch text analyzer is not aware that “went” is the base form of “go”. While an English analyzer uses stemming to keep track of such things.
as a result, knowing which language you want your articles to be searched will drastically increase the relevance score of found articles.
Logging is another important thing that we want to implement. Most likely, we will use Elasticsearch for logging.
Elasticsearch recovery plan should also be implemented. At least, we should be aware when the cluster is down (which is not the case at the moment).
Conclusion
It just works. What else do you need from a beta?
Two main things that helped us along working on the beta:
- asking Reddit to help us with our architecture
- Investing some time to release our Python package → getting beta sign-ups
Thank you for reading all the way down here.
The best way to support us is to check how our News API looks right now.




.png)





































