































This guide walks through building an iterative research agent that combines NewsCatcher's CatchAll API with CrewAI's agent framework. The result is a system that can take a natural language research question, search for relevant news, evaluate results, and synthesize findings into a comprehensive report.
Architecture Overview
The system uses a flow-based architecture where each step triggers the next:
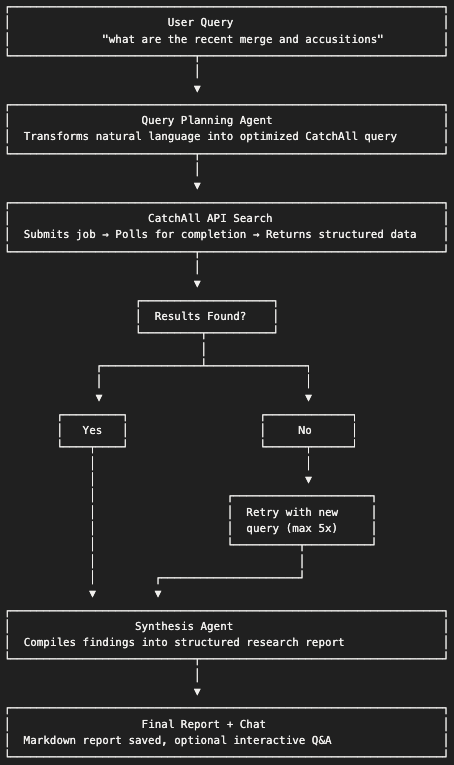
Why this architecture?
- Iterative searching handles cases where initial queries return no results
- Agent-based planning adapts queries based on the user's intent
- Structured synthesis produces consistent, citable reports
- Flow orchestration manages state across the pipeline
Prerequisites
- Python 3.10+
- Newscatcher CatchAll API key
- Google Gemini API key
Project Setup
1. Create project structure
mkdir deep_search_agent && cd deep_search_agent2. Define dependencies
Create pyproject.toml:
[project]
name = "deep_search_agent"
version = "1.0.0"
requires-python = ">=3.10"
dependencies = [
"crewai[tools]>=0.86.0",
"newscatcher-catchall-sdk>=0.2.0",
"python-dotenv>=1.0.0",
"google-generativeai>=0.8.0",
]
[project.scripts]
kickoff = "deep_search_agent.main:run"
[tool.crewai]
type = "flow"
[build-system]
requires = ["hatchling"]
build-backend = "hatchling.build"
[tool.hatch.build.targets.wheel]
packages = ["src/deep_search_agent"]3. Install
crewai install4. Configure environment
Create .env in the project root:
MODEL=gemini/gemini-2.5-flash
CHAT_MODEL=gemini-2.5-flash
NEWSCATCHER_API_KEY=your_catchall_key
GEMINI_API_KEY=your_gemini_keyBuilding the CatchAll Tool
The CatchAll tool wraps the API into a CrewAI-compatible interface. Key responsibilities:
- Submit a search job with query, context, and extraction schema
- Poll until the job completes (can take 1-10 minutes)
- Return structured results
Create src/deep_search_agent/tools/catchall_tool.py:
import os
import time
import json
from datetime import datetime
from typing import Type, Optional, Any, Dict
from crewai.tools import BaseTool
from pydantic import BaseModel, Field
class CatchAllInput(BaseModel):
query: str = Field(..., description="Natural language search query")
context: Optional[str] = Field(default=None, description="Extraction guidance")
schema: Optional[str] = Field(default=None, description="Output structure")
class CatchAllTool(BaseTool):
name: str = "catchall_search"
description: str = "Search news articles using Newscatcher CatchAll API"
args_schema: Type[BaseModel] = CatchAllInput
def _run(self, query: str, context: str = None, schema: str = None) -> str:
from newscatcher_catchall import CatchAllApi
api_key = os.getenv("NEWSCATCHER_API_KEY")
if not api_key:
return json.dumps({"error": "API key not set", "records": []})
client = CatchAllApi(api_key=api_key)
# Build job parameters
params = {"query": query}
if context:
params["context"] = context
if schema:
params["schema"] = schema
# Submit job
job = client.jobs.create_job(**params)
job_id = job.job_id
# Poll for completion (30 min timeout)
for elapsed in range(0, 1800, 30):
status = client.jobs.get_job_status(job_id)
# Check if any step shows completion
if any(s.status == "completed" and s.completed for s in status.steps):
break
if all(s.completed for s in status.steps):
break
time.sleep(30)
else:
return json.dumps({"error": "timeout", "records": []})
# Fetch results
results = client.jobs.get_job_results(job_id)
return json.dumps({
"query": query,
"valid_records": results.valid_records,
"records": self._serialize(results.all_records)
}, indent=2)
def _serialize(self, obj) -> Any:
"""Convert API response objects to JSON-serializable dicts."""
if obj is None or isinstance(obj, (str, int, float, bool)):
return obj
if isinstance(obj, datetime):
return obj.isoformat()
if isinstance(obj, dict):
return {k: self._serialize(v) for k, v in obj.items()}
if isinstance(obj, (list, tuple)):
return [self._serialize(i) for i in obj]
if hasattr(obj, "model_dump"):
return self._serialize(obj.model_dump())
if hasattr(obj, "__dict__"):
return {k: self._serialize(v) for k, v in obj.__dict__.items()
if not k.startswith("_")}
return str(obj)
Key points:
- The tool blocks until results are ready—this is intentional for sequential flow execution
- Timeout is set to 30 minutes to accommodate large searches
- Results are serialized to handle Pydantic models from the SDK
Creating the Search Flow
CrewAI Flows manage state and orchestrate execution. Our flow has three stages:
- Search loop — Plan query, execute search, retry if empty
- Synthesize — Generate report from collected results
- Complete — Return final output
Create src/deep_search_agent/flow.py:
import json
import re
from typing import Optional, List, Dict, Any
from pydantic import BaseModel, Field
from crewai.flow.flow import Flow, listen, start
from deep_search_agent.tools.catchall_tool import CatchAllTool
from deep_search_agent.crews import QueryPlanner, Synthesizer
class Iteration(BaseModel):
query: str
context: Optional[str] = None
records_found: int = 0
results: Optional[Dict] = None
class SearchState(BaseModel):
prompt: str = ""
max_iterations: int = 5
current: int = 0
iterations: List[Iteration] = Field(default_factory=list)
all_results: List[Dict] = Field(default_factory=list)
report: str = ""
class DeepSearchFlow(Flow[SearchState]):
def __init__(self):
super().__init__()
self.tool = CatchAllTool()
@start()
def search_loop(self):
"""Execute iterative search until results found or max reached."""
while self.state.current < self.state.max_iterations:
self.state.current += 1
# Plan the query
plan = self._plan_query()
iteration = Iteration(
query=plan["query"],
context=plan.get("context")
)
self.state.iterations.append(iteration)
# Execute search
raw = self.tool._run(
query=iteration.query,
context=iteration.context,
schema=plan.get("schema")
)
results = json.loads(raw)
iteration.results = results
iteration.records_found = results.get("valid_records", 0)
# Check results
if iteration.records_found > 0:
self.state.all_results.append(results)
break
# No results — loop continues with refined query
@listen(search_loop)
def synthesize(self):
"""Generate final report from collected results."""
if not self.state.all_results:
self.state.report = self._empty_report()
return
# Format results for the synthesis agent
formatted = self._format_results()
result = Synthesizer().crew().kickoff(inputs={
"prompt": self.state.prompt,
"results": formatted
})
self.state.report = str(result)
@listen(synthesize)
def complete(self):
return self.state.report
def _plan_query(self) -> Dict:
"""Use agent to plan search query."""
previous = [it.query for it in self.state.iterations]
result = QueryPlanner().crew().kickoff(inputs={
"prompt": self.state.prompt,
"iteration": self.state.current,
"previous_queries": previous or ["None"]
})
# Extract JSON from agent response
return self._parse_json(str(result)) or {"query": self.state.prompt}
def _parse_json(self, text: str) -> Optional[Dict]:
"""Extract JSON object from text."""
patterns = [
r'```json\\s*([\\s\\S]*?)\\s*```',
r'```\\s*([\\s\\S]*?)\\s*```',
r'\\{[\\s\\S]*\\}'
]
for pattern in patterns:
match = re.search(pattern, text)
if match:
try:
content = match.group(1) if match.lastindex else match.group(0)
return json.loads(content)
except json.JSONDecodeError:
continue
return None
def _format_results(self) -> str:
"""Format results for synthesis."""
lines = []
for results in self.state.all_results:
for rec in results.get("records", []):
title = rec.get("record_title", "Untitled")
lines.append(f"## {title}")
enrichment = rec.get("enrichment", {})
if enrichment.get("schema_based_summary"):
lines.append(enrichment["schema_based_summary"])
citations = rec.get("citations", [])[:3]
if citations:
sources = ", ".join(f"[{c.get('title', '')}]({c.get('link', '')})"
for c in citations)
lines.append(f"Sources: {sources}")
lines.append("")
return "\\n".join(lines)
def _empty_report(self) -> str:
queries = "\\n".join(f"- {it.query}" for it in self.state.iterations)
return f"""# Research Report
**Query:** {self.state.prompt}
No results found after {self.state.current} attempts.
## Queries Attempted
{queries}
Consider using broader search terms.
"""
Flow execution order:
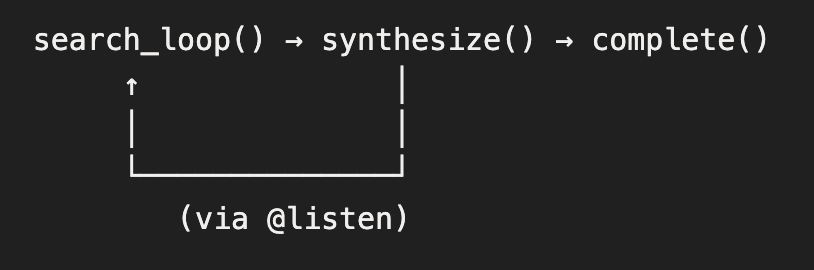
The @start() decorator marks the entry point. @listen() decorators wire up the sequence—synthesize runs after search_loop completes.
Defining Agents
Agents handle the intelligent parts: query planning, result evaluation, and report synthesis. Each agent has a specific role in the pipeline.
Agent Configuration (YAML)
Create src/deep_search_agent/config/agents.yaml:
query_strategist:
role: Search Query Strategist
goal: >
Transform user prompts into effective search queries that yield
comprehensive news results from the CatchAll API.
backstory: >
Expert in information retrieval. You construct queries that balance
specificity with coverage:
- Target newsworthy events (acquisitions, launches, funding)
- Include 2-4 constraints (industry, geography, threshold)
- Use single entity or related categories
- Focus on recent events
result_evaluator:
role: Search Quality Analyst
goal: >
Evaluate search results for quality and completeness.
Determine if results are sufficient or need refinement.
backstory: >
Meticulous quality analyst. You assess results based on:
- Relevance to original query
- Number and quality of records
- Coverage of topic aspects
- Recency and credibility
research_synthesizer:
role: Research Synthesis Specialist
goal: >
Compile search results into a comprehensive research report
that fully answers the user’s question.
backstory: >
Expert research analyst. Your reports feature:
- Clear executive summaries
- Well-organized sections by theme
- Proper source attribution with links
- Actionable conclusionsAgent Definitions (Python)
Create src/deep_search_agent/crews.py:
import os
from crewai import Agent, Crew, Process, Task, LLM
def llm(temp=0.3):
return LLM(
model="gemini/gemini-2.5-flash",
api_key=os.getenv("GEMINI_API_KEY"),
temperature=temp
)
class QueryPlannerCrew:
"""Plans effective CatchAll queries from user prompts."""
def crew(self):
agent = Agent(
role="Query Specialist",
goal="Create effective search queries",
backstory=(
"Expert at CatchAll queries. Rules: simple natural language, "
"one event type, no dates/operators. "
"Examples: 'AI acquisitions', 'supply chain disruptions at automakers'"
),
llm=llm(0.3),
verbose=True,
max_iter=3 # Limit reasoning iterations
)
task = Task(
description=(
"Query for: {user_prompt}\\n"
"Iteration {iteration_number}/{max_iterations}\\n"
"Previous: {previous_queries}\\n"
"Results: {previous_results_summary}\\n"
"If retrying, use broader terms."
),
expected_output='{"query": "...", "context": "...", "schema": "..."}',
agent=agent
)
return Crew(
agents=[agent],
tasks=[task],
process=Process.sequential,
verbose=True
)
class ResultEvaluatorCrew:
"""Evaluates if search results are sufficient."""
def crew(self):
agent = Agent(
role="Quality Analyst",
goal="Evaluate search result quality",
backstory="Assesses if results answer the query adequately.",
llm=llm(0.2), # Lower temp for consistent evaluation
verbose=True,
max_iter=3
)
task = Task(
description=(
"Evaluate: {user_prompt}\\n"
"Query: {current_query}\\n"
"Results: {search_results}"
),
expected_output='{"is_sufficient": bool, "quality_score": 1-10, "gaps": [...]}',
agent=agent
)
return Crew(
agents=[agent],
tasks=[task],
process=Process.sequential,
verbose=True
)
class ResearchSynthesizerCrew:
"""Synthesizes search results into a research report."""
def crew(self):
agent = Agent(
role="Research Writer",
goal="Create comprehensive research reports",
backstory="Writes clear reports with findings, citations, and conclusions.",
llm=llm(0.4), # Slightly higher temp for better writing
verbose=True,
max_iter=5
)
task = Task(
description=(
"Report for: {user_prompt}\\n\\n"
"Data:\\n{all_results}\\n\\n"
"Include: summary, key findings, sources, conclusions."
),
expected_output="Markdown report with citations",
agent=agent
)
return Crew(
agents=[agent],
tasks=[task],
process=Process.sequential,
verbose=True
)Task Configuration (YAML)
Create src/deep_search_agent/config/tasks.yaml:
plan_search_query:
description: >
Create an optimal search query for the CatchAll API.
USER PROMPT: {user_prompt}
ITERATION: {iteration_number} of {max_iterations}
PREVIOUS QUERIES: {previous_queries}
PREVIOUS RESULTS: {previous_results_summary}
Tasks:
1. Understand user intent
2. Identify entities, events, constraints
3. Craft query following CatchAll best practices
4. Create extraction context and schema
If retrying, adjust based on what didn't work.
expected_output: >
{"query": "...", "context": "...", "schema": "...", "reasoning": "..."}
agent: query_strategist
evaluate_results:
description: >
Evaluate if search results answer the user's question.
PROMPT: {user_prompt}
QUERY: {current_query}
RESULTS: {search_results}
Factors:
- 0 records = retry with different query
- Low relevance = adjust focus
- Good coverage = sufficient
expected_output: >
{"is_sufficient": bool, "quality_score": 1-10, "gaps": [...]}
agent: result_evaluator
synthesize_research:
description: >
Compile results into a comprehensive research report.
PROMPT: {user_prompt}
RESULTS: {all_results}
Structure:
- Executive summary
- Findings by theme
- Citations with links
- Key takeaways
expected_output: >
Markdown report with citations and conclusions.
agent: research_synthesizerAgent Design Principles
- Keep backstories short and focused on capabilities
- Use lower temperatures (0.2-0.3) for query planning and evaluation
- Use slightly higher temperature (0.4) for creative synthesis
- Limit
max_iterto prevent infinite loops - Match expected output to the format you need to parse
Running the Agent
Create src/deep_search_agent/main.py:
import os
import json
from datetime import datetime
from pathlib import Path
from dotenv import load_dotenv
load_dotenv()
def run(prompt=None, max_iterations=5):
from deep_search_agent.flow import DeepSearchFlow
prompt = prompt or input("Research query: ").strip()
if not prompt:
return
print(f"\\n🔍 Searching: {prompt}\\n")
flow = DeepSearchFlow()
flow.state.prompt = prompt
flow.state.max_iterations = max_iterations
flow.kickoff()
# Save report
Path("reports").mkdir(exist_ok=True)
filename = f"reports/report_{datetime.now():%Y%m%d_%H%M%S}.md"
Path(filename).write_text(flow.state.report)
print(f"\\n📄 Saved: {filename}")
print(f"\\n{flow.state.report[:500]}...")
return flow.state.report
if __name__ == "__main__":
run()Execute
crewai run
Or with a specific query
DEEP_SEARCH_PROMPT="semiconductor supply chain disruptions" crewai runAdding Follow-up Chat
After generating a report, users often want to ask follow-up questions. We can add an interactive chat that has full context of the research.
Add to main.py:
def chat(report, results):
"""Interactive Q&A about the research."""
import google.generativeai as genai
genai.configure(api_key=os.getenv("GEMINI_API_KEY"))
model = genai.GenerativeModel("gemini-2.5-flash")
# Build context from report and raw data
context = f"Research Report:\\n\\n{report}\\n\\n"
context += "Raw Data:\\n" + json.dumps(results, indent=2)[:50000] # Truncate if needed
session = model.start_chat(history=[
{"role": "user", "parts": [f"Context:\\n{context}\\n\\nAnswer questions about this research."]},
{"role": "model", "parts": ["Ready to answer questions about the research."]}
])
print("\\n💬 Chat (type 'exit' to quit)\\n")
while True:
try:
q = input("You: ").strip()
if q.lower() in ['exit', 'quit']:
break
if q:
response = session.send_message(q)
print(f"\\nAssistant: {response.text}\\n")
except (EOFError, KeyboardInterrupt):
breakResults Report Snippet
# Recent Mergers and Acquisitions in the Tech Space (Last Week)
## Executive Summary
The past week has seen a dynamic landscape of mergers and acquisitions (M&A) across the technology sector, reflecting strategic shifts towards AI integration, digital transformation, market consolidation, and expansion into emerging technologies. Key trends include significant investments in AI capabilities, particularly in areas like video, data security, and robotics; continued consolidation within the streaming, telecommunications, and fintech industries; and strategic moves to enhance market presence in specialized tech niches such as space technology, quantum computing, and e-commerce. Notable deals range from multi-billion dollar acquisitions by industry giants like Marvell and IBM to smaller, targeted purchases by emerging players, underscoring a broad and active M&A environment.
## Organized Findings
### 1. Artificial Intelligence (AI) and Data Technologies
AI and data-centric acquisitions were a dominant theme, indicating a strong industry focus on enhancing intelligent capabilities and data management.
**Marvell Technology** is set to acquire **Celestial AI** for over $3.25 billion, aiming to accelerate scale-up connectivity for next-generation data centers, highlighting the critical role of AI in infrastructure [5].
**Avalon GloboCare Corp.** acquired **RPM Interactive, Inc.**, an AI video firm, for $19.5 million, expanding its reach into AI-powered video solutions [4].
**Disney** acquired a stake in **OpenAI**, signaling a collaboration for AI content creation, particularly for platforms like Sora [23].
**Meta** acquired AI wearable startup **Limitless**, indicating a push into AI-powered personal devices [79].
**Veeam Software** acquired **Securiti AI** to bolster its AI data security and governance offerings [83].
**Rezolve Ai** expanded its AI Digital Experience Platform (DXP) with the acquisition of **Crownpeak** [58].
**Doosan Robotics** acquired **One Exia** to enhance its AI and robotics capabilities, focusing on "Physical AI" [44].
**Stirling Square Capital Partners** acquired a majority stake in **Iconsulting SpA** to accelerate its growth as a European leader in data and AI services [49].
**Beixinyuan System Integration Co.Ltd.’s** subsidiary invested in AI translation company **Beijing Aichuan Zhisheng Technology Co., Ltd.** to expand its industrial layout in related fields [71].
**Palladyne AI Corp** acquired defense companies **GuideTech LLC, Warnke Precision Machining, and MKR Fabricators**, indicating AI integration into defense manufacturing [72].
**The Data Appeal Company** acquired a majority stake in **Mabrian Technologies**, likely for enhancing data analytics and insights [52].
### 2. Cloud, Software, and Digital Services
Strategic acquisitions in software and digital services aim to expand platforms, improve offerings, and consolidate market positions.
**IBM** reached an agreement to acquire **Confluent** for $11 billion, a significant move to enhance its cloud and data streaming capabilities [66, 77].
**Adobe** is set to acquire **Semrush** for $1.9 billion, expanding its digital marketing and analytics portfolio [8].
**TCS (Tata Consultancy Services)** acquired **Coastal Cloud** for $700 million, strengthening its Salesforce services [31].
**Freshworks Inc.** acquired AI incident management platform **FireHydrant** to boost its AI-powered incident management solutions [41].
**Proofpoint, Inc.** completed its acquisition of **Hornetsecurity Group**, enhancing its data protection and cybersecurity offerings [46].
**Netcall** acquired **Jadu Holdings** for up to £19.2 million, expanding its digital services for UK and US public sectors [100].
**Diginex Limited** acquired **Matter DK ApS** to enhance its ESG (Environmental, Social, and Governance) compliance platform [57].
**Warburg Pincus** is nearing the completion of its takeover offer for **PSI Software** [34].
**Broadcom’s** acquisition of **VMware** continues to face challenges, with CISPE contesting the EU’s approval, citing concerns over price increases and customer lock-in [35, 43].
### 3. Telecommunications and Connectivity
...
## Citations
[1] FAE Technology acquisisce Kayser Italia e lancia la nuova divisione Space. (2025, December 16). *Teleborsa*.
[2] Pinterest To Acquire CTV Ad Company. (2025, December 16). *MediaPost*.
[3] Anonymous signs LOI to acquire 100 crypto mining rigs. (2025, December 16). *Stockwatch*.
[4] EXCLUSIVE: Avalon GloboCare Buys AI Video Firm In 19.5 Million Deal. (2025, December 16). *Yahoo Finance*.
[5] Marvell to Acquire Celestial AI, Accelerating Scale-up Connectivity for Next-Generation Data Centers. (2025, December 15). *StorageNewsletter*.
...Summary
This integration combines:
- CatchAll for deep news search with structured extraction
- CrewAI Flows for stateful, iterative execution
- LLM agents for query planning and report synthesis
The result is a research agent that can handle complex questions, adapt when initial searches fail, and produce citable reports—all with a clean, maintainable architecture.



































